Train PyTorch models directly from a Rerun server.
The experimental dataloader module exposes Rerun recordings as iterable or map-style PyTorch datasets, decoding compressed video (h264/h265/av1), images, and scalars on the fly. Random access, multi-worker prefetching, and DDP partitioning all work out of the box.
The full code for this guide lives in examples/python/dataloader/, which trains a LeRobot ACT policy from a HuggingFace dataset.

Training sample construction
A vision-language-action policy is trained on samples that align several columns of multimodal data at the same instant in time:
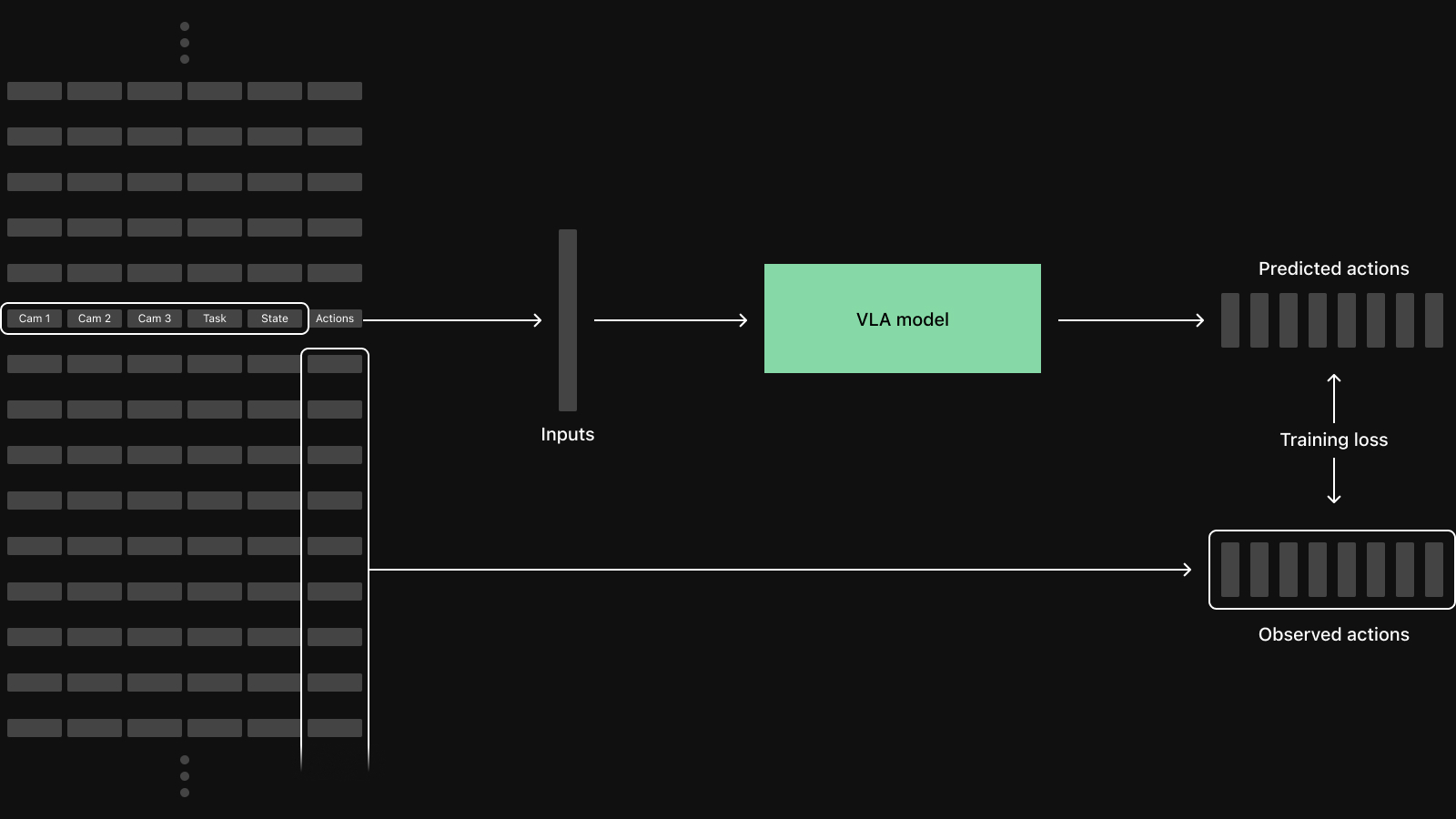
The dataloader assembles those samples on demand from the per-recording chunks in a Rerun catalog, while the PyTorch DataLoader drives batching, shuffling, and worker parallelism.
How to use it
Register data with a catalog
The dataloader reads from a Rerun catalog, so you must first register RRDs. Start the OSS server in a separate terminal:
rerun serverThen register your recordings. Each registered RRD becomes a segment in the dataset, typically one episode or trajectory per RRD:
client = rr.catalog.CatalogClient(server.url())
dataset = client.create_dataset("my_robot_data", exist_ok=True)
uris = [f"file://{p.resolve()}" for p in rrd_paths]
dataset.register(uris).wait()The example's prepare_dataset.py shows the full flow for converting a HuggingFace LeRobot dataset into per-episode RRDs and registering them.
Describe a sample
A Rerun dataset is built from three things:
- a
DataSource: the catalog dataset and an optional segment filter - an
index: the timeline that defines what "one sample" means (e.g."real_time"or"frame_index") - a dict of
Fields: what each sample should contain
from rerun.experimental.dataloader import (
DataSource,
Field,
FixedRateSampling,
NumericDecoder,
RerunIterableDataset,
)
source = DataSource(
dataset=client.get_dataset("my_robot_data"),
segments=[
"ILIAD_50aee79f_2023_07_12_20h_55m_08s",
"ILIAD_5e938e3b_2023_07_20_10h_40m_10s",
],
)
fields = {
"state": Field(
"/observation/joint_positions:Scalars:scalars", decode=NumericDecoder()
),
"action": Field(
"/action/joint_positions:Scalars:scalars", decode=NumericDecoder()
),
}
ds = RerunIterableDataset(
source=source,
index="real_time",
fields=fields,
timeline_sampling=FixedRateSampling(rate_hz=15.0),
)Each Field.path is a column name from the dataset's catalog schema. The decoder turns that column into a tensor:
NumericDecoder()for scalar and list-of-scalar columnsImageDecoder()for encoded image blobs (JPEG/PNG)VideoFrameDecoder(codec=…)for compressed video (h264/h265/av1)
The dict keys ("state", "action", …) in fields become the keys of each sample dict that the dataset yields. When the index is a timestamp timeline (like "real_time" above), pass timeline_sampling=FixedRateSampling(rate_hz=…) so the dataloader knows how to lay out the sampling grid.
Action chunks and history via window
Field(window=(start, end)) returns a slice of values across that inclusive range relative to the current index, instead of a single value:
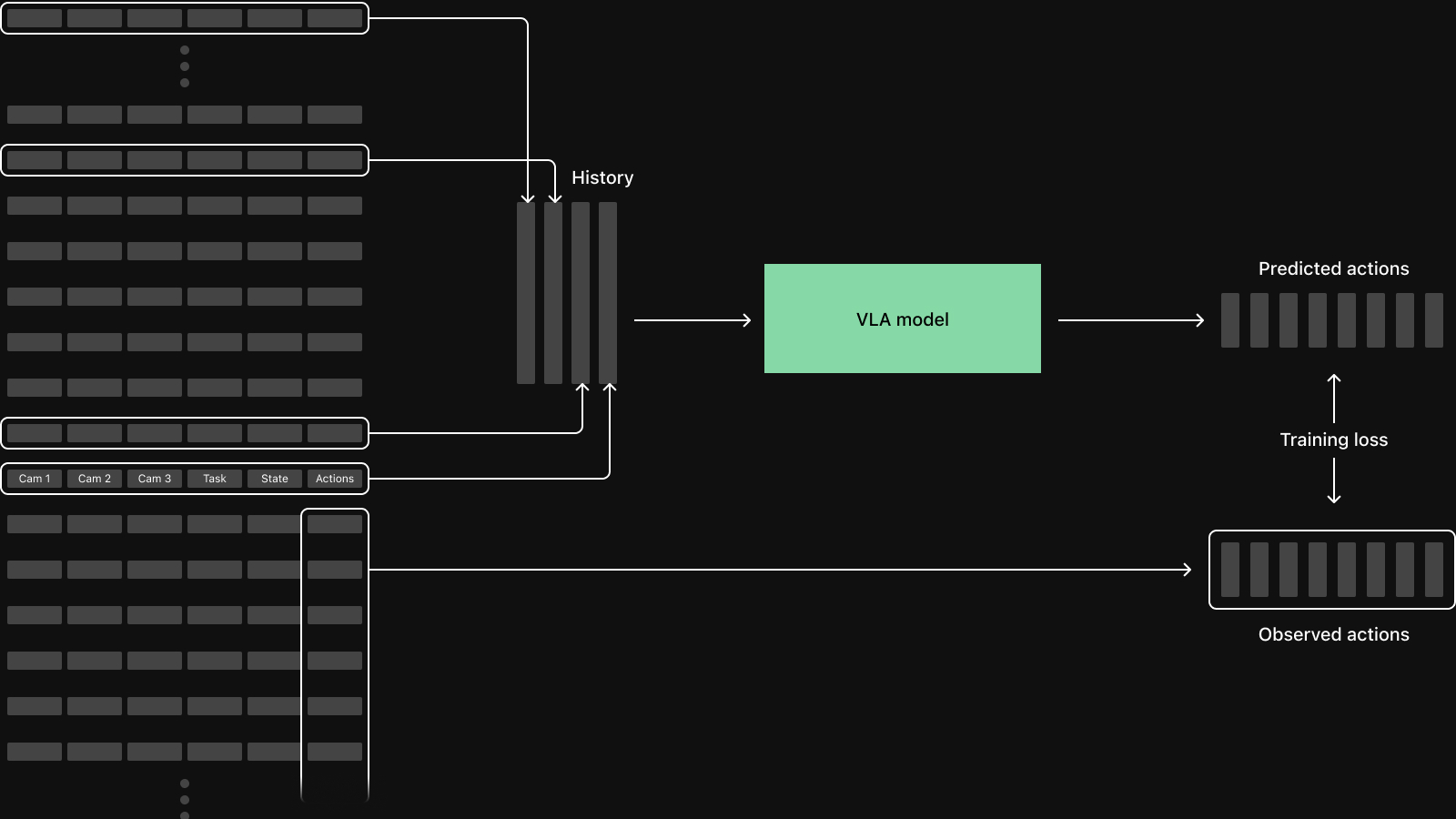
# Each sample now carries the next 50 action steps instead of a single value.
# Offsets are in the index timeline's native unit: integer steps for integer
# indices, or nanoseconds for timestamp indices (use multiples of the
# FixedRateSampling period).
windowed_action = Field(
"/action/joint_positions:Scalars:scalars",
decode=NumericDecoder(),
window=(1, 50),
)The example uses this to feed 50-step action chunks into the ACT policy.
Video decoding is GOP-aware
A VideoFrameDecoder looks like a regular field from the outside, but decoding any one frame of compressed video requires running the codec from the previous keyframe forward through the target frame. The chain of frames the codec has to walk through is bounded by the GOP length:
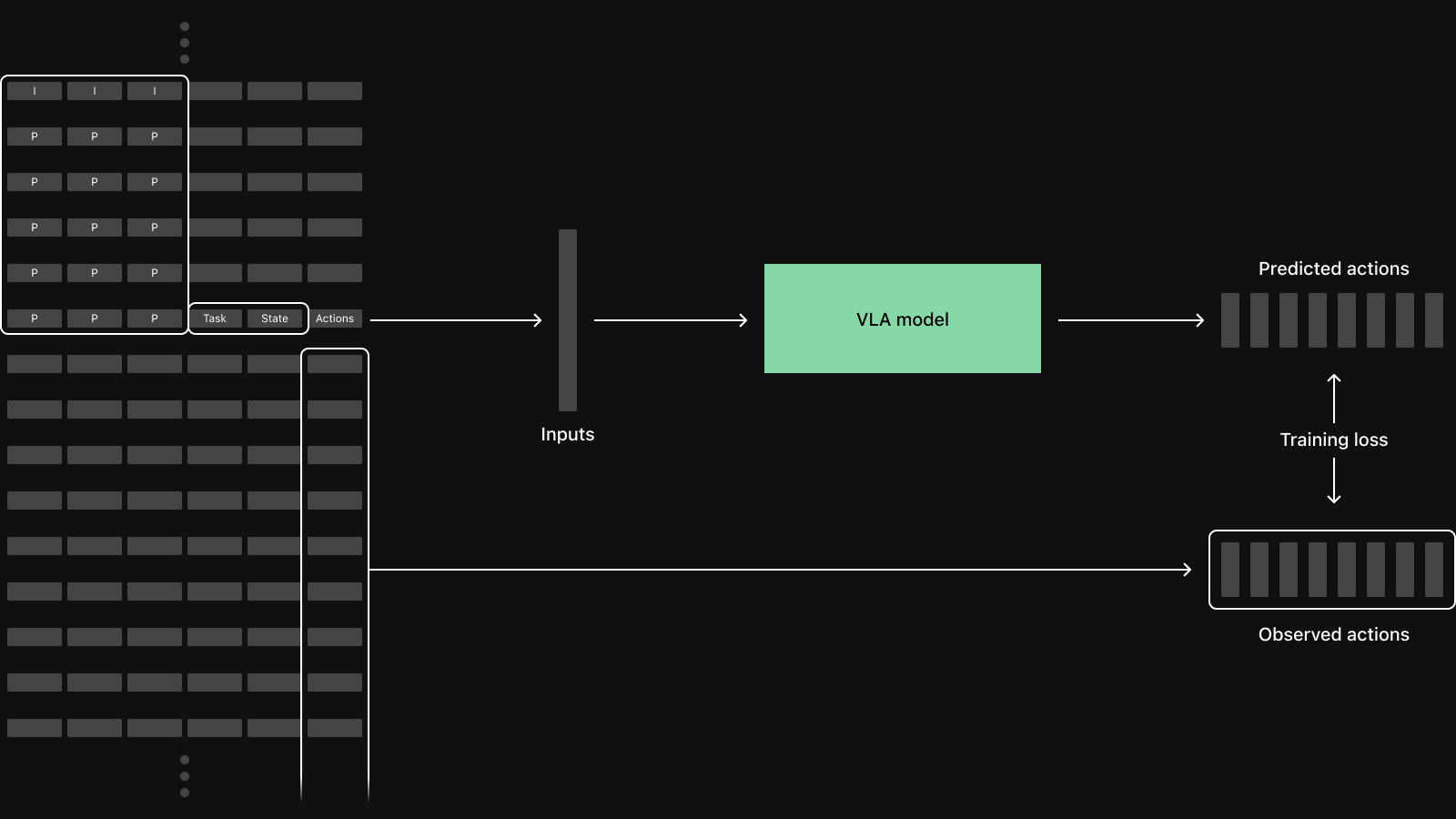
# Decode a compressed video stream as part of each sample.
# `keyframe_interval` must be at least the actual GOP length. For timestamp
# timelines, `fps_estimate` should also approximate the true frame rate.
from rerun.experimental.dataloader import VideoFrameDecoder
image_field = Field(
"/camera/wrist:VideoStream:sample",
decode=VideoFrameDecoder(
codec="h264", keyframe_interval=500, fps_estimate=15.0
),
)The dataloader handles this transparently. VideoFrameDecoder.context_range asks the prefetcher for a window of preceding samples ending at the target, sized to be guaranteed to span at least one keyframe; the codec runs over the fetched packets in order and returns the frame at the target index. You only need to pass keyframe_interval, which must be greater than or equal to the actual GOP length; for timestamp timelines, also pass an fps_estimate that approximates the true frame rate.
Iterable vs. Map-style
The dataloader provides both PyTorch dataset styles:
RerunIterableDataset: streaming iteration with internal shuffling (on by default) and cross-worker partitioning. Good default. Callds.set_epoch(epoch)to reseed the shuffle between epochs.RerunMapDataset: random access by global index, plugs into PyTorch's sampler ecosystem (DistributedSampler,WeightedRandomSampler,SubsetRandomSampler, …).
Wrap either in torch.utils.data.DataLoader:
from torch.utils.data import DataLoader
from rerun.experimental.dataloader import RerunMapDataset
def my_collate(
samples: list[dict[str, torch.Tensor]],
) -> dict[str, torch.Tensor]:
# Drop samples that landed outside the underlying data (FixedRateSampling
# may overshoot the end of a segment by one grid point).
samples = [
s for s in samples if s["state"].numel() > 0 and s["action"].numel() > 0
]
return {
"state": torch.stack([s["state"] for s in samples]).float(),
"action": torch.stack([s["action"] for s in samples]).float(),
}
loader = DataLoader(
ds,
batch_size=8,
num_workers=0,
shuffle=isinstance(ds, RerunMapDataset), # iterable shuffles internally
collate_fn=my_collate,
)For DDP, the iterable dataset partitions the index list across ranks automatically. With the map dataset, swap in sampler=DistributedSampler(ds) and call sampler.set_epoch(epoch) each epoch.
Train
From there, the training loop is standard PyTorch:
for epoch in range(epochs):
if isinstance(ds, RerunIterableDataset):
ds.set_epoch(epoch)
for batch in loader:
batch = {k: v.to(device) for k, v in batch.items()}
loss, _ = policy.forward(batch)
loss.backward()
optimizer.step()
optimizer.zero_grad()The full LeRobot ACT example wires this up against three camera streams plus state and action chunks, and trains the policy end-to-end.
Limitations
The module is experimental: expect breaking changes between releases as we iterate on the design.
For large-scale training (hundreds of recordings, multi-node), consider Rerun Hub, which offers a higher-performance backend than the OSS catalog.
References
- LeRobot ACT training example
rerun.experimental.dataloadermodule source- The data layer tax in robot learning (figures used in this guide)
- Export recordings to LeRobot datasets (inverse: Rerun → LeRobot dataset)