The data layer tax for robot learning
Scaling laws are starting to work for robotics, producing capabilities that were unthinkable just a few years ago. End-to-end models predict robot actions directly from sensor inputs, which simplifies the on-robot software but makes everything from data collection to training dramatically harder. LLM teams scaled on mature data infrastructure to improve performance through fast iteration on data. Robotics teams are trying to scale without it.
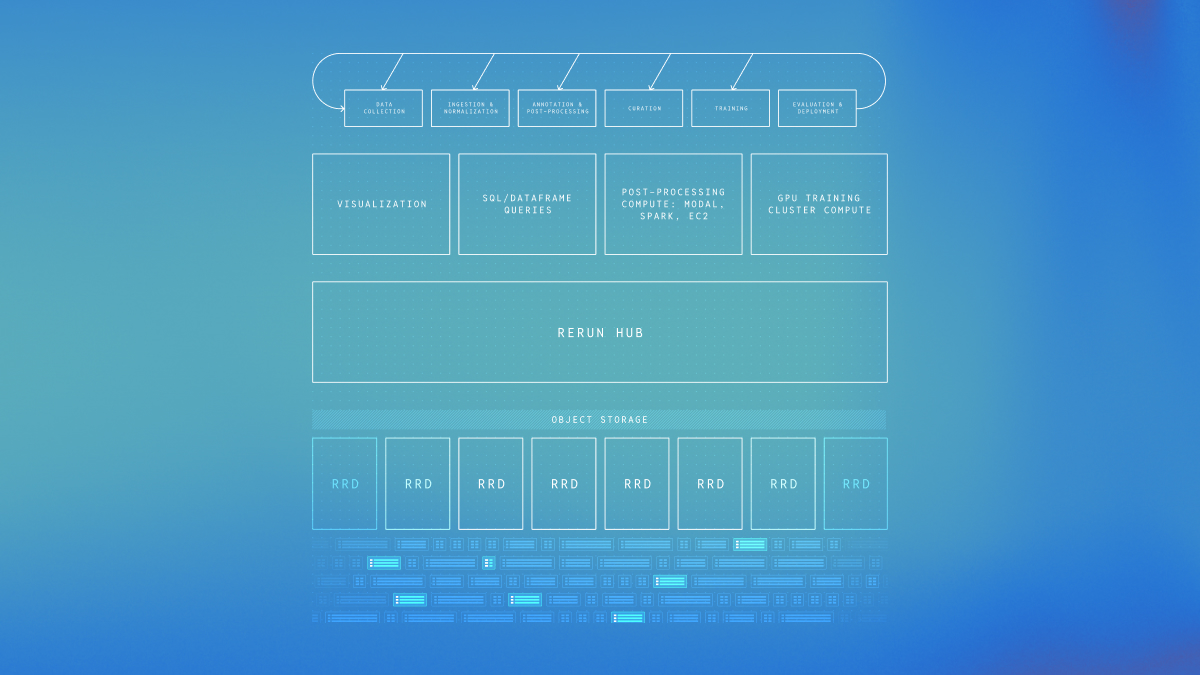
Most teams build data tooling from scratch because existing infrastructure wasn't designed for the multi-rate and multimodal data that powers robotics learning. Across the data journey from collection to training, common operations are harder and slower than they should be. The cumulative cost, in iteration speed, engineering focus, and GPU utilization, is what we'll call the data layer tax. Reducing this tax is a major lever to move faster and scale in the race towards what looks like the biggest market the world has ever seen.
Architecturally, the data layer owns storing, modeling, and accessing data. The data layer for Physical AI is still immature, and the cost is visible at every stage of the pipeline.
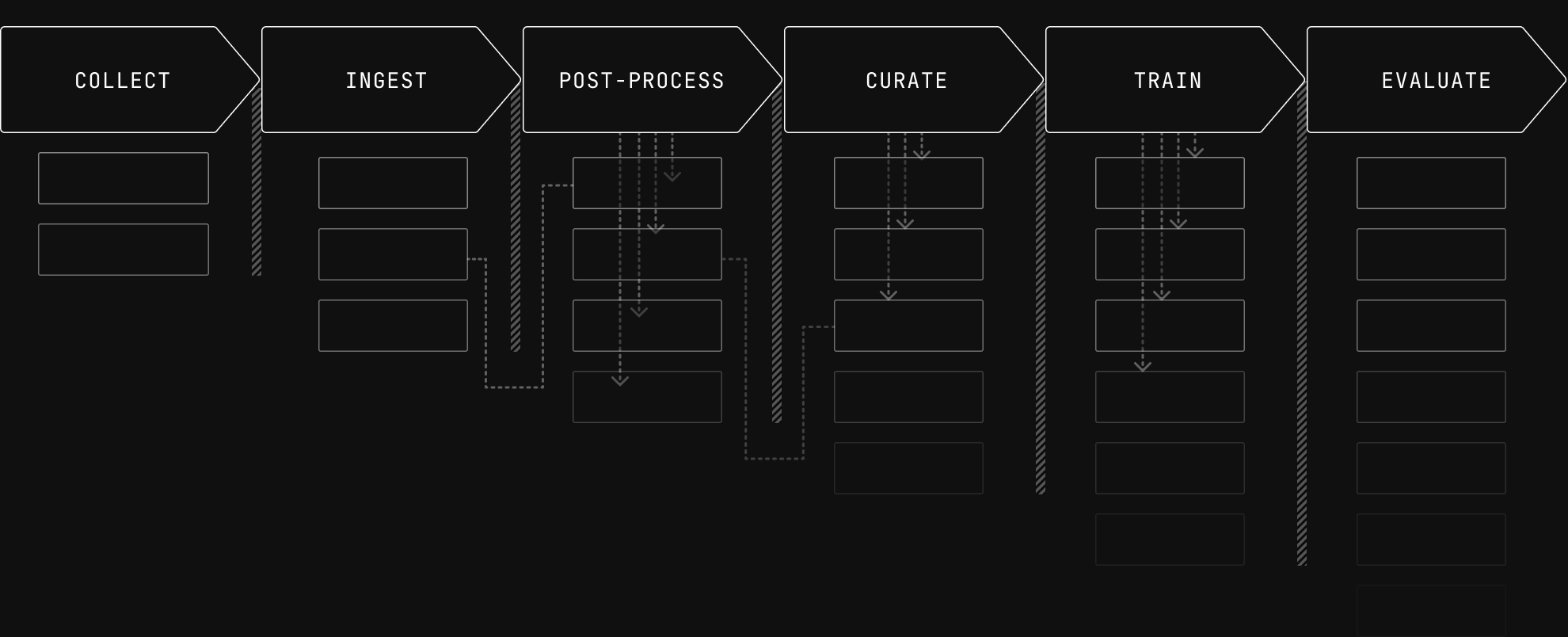
If you're building or investing in robot learning, this post is a map of where that tax comes from. We'll walk backwards from evaluation to collection, showing how requirements cascade upstream and why the tax compounds with data scale, source variety, and curation sophistication.
Policy evaluation
An extensive set of “evals” is core to any LLM team’s ability to make rapid progress. Evaluation of robot behavior is much more difficult, which has a cascading effect on the entire pipeline. For robotics teams, even a small real-world evaluation on a trained policy takes hours or days of robot trials and careful design and operations. This means making rapid progress against extensive, repeatable, and fast evals aren’t feasible in robotics.
Teams instead rely on proxy metrics that score data quality directly, things like reward models that assess task progress, 3D reconstruction quality as a signal for calibration correctness, or just estimating the jerkiness of trajectories. These tell you whether individual episodes or samples look good or bad, not whether they produce a better policy.
Since real evaluation runs are harder to do, it’s important to study each one deeply. Many important decisions come from researchers who are deeply steeped in the data, watching eval rollouts and using their intuition about the full system to decide how to proceed.
From a data infrastructure perspective, evaluation looks a lot like collection. You record model inputs, outputs, and targets along with metadata like model version, subtask, and environment configuration. Researchers then review large numbers of rollouts, aggregate them by metrics, and drill into specific recordings.
Tracing a rollout back to the training data that caused it often requires manual detective work across disconnected tools and formats. Every point of friction adds up to slower iteration times and insights that don’t feed back to training better policies.
Model training
Robot behavior learning shares many foundations with other machine learning tasks. What changes is that these models output actions over time. This added time dimension drastically increases the complexity of the data layer that supports training for two key reasons: sample construction and video compression.
Sample construction during training
When training large models, we must feed the expensive GPUs data fast enough to maximize utilization. Researchers steer the behavior of the model by selecting what data to include and how to sample it.
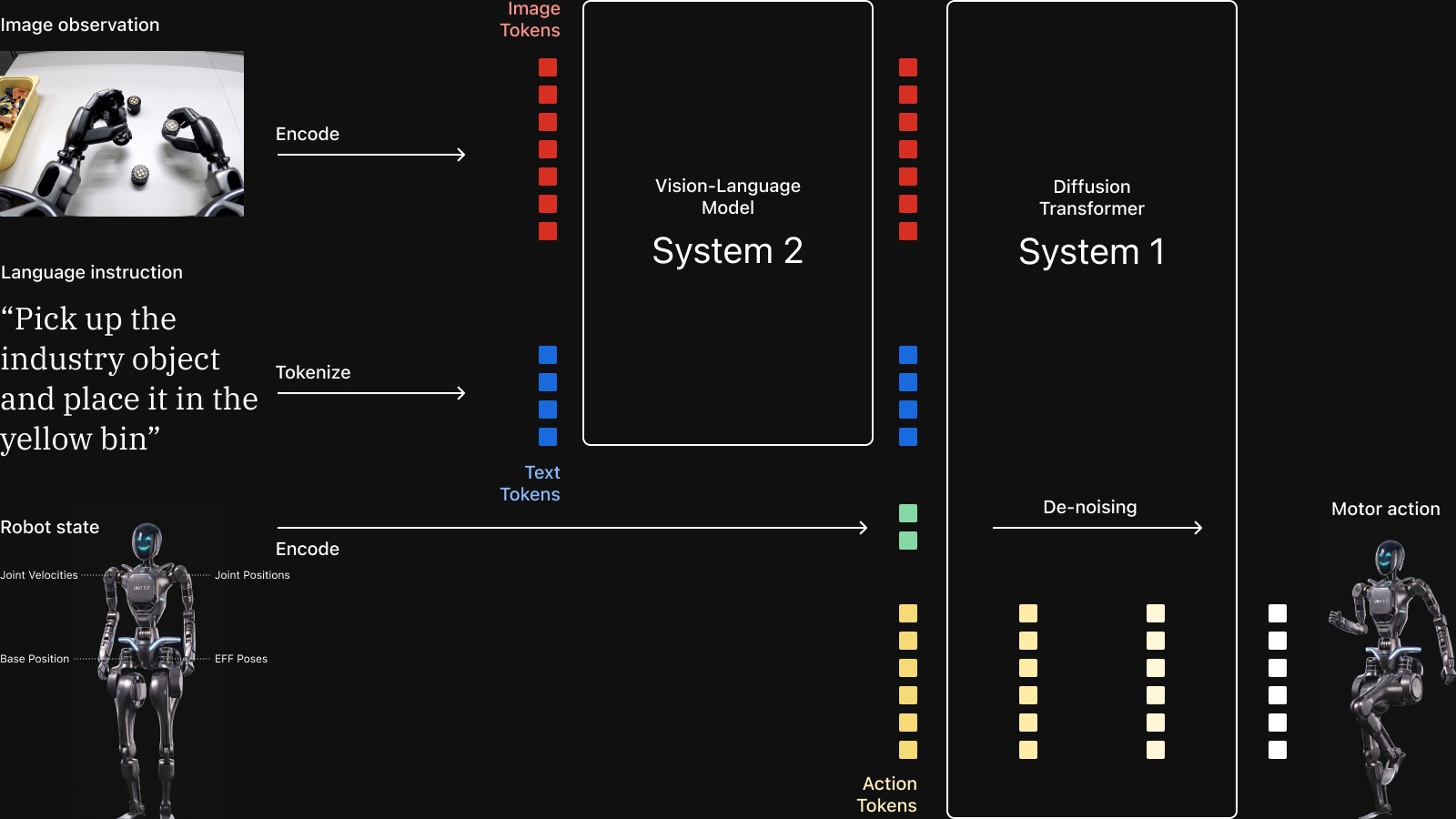
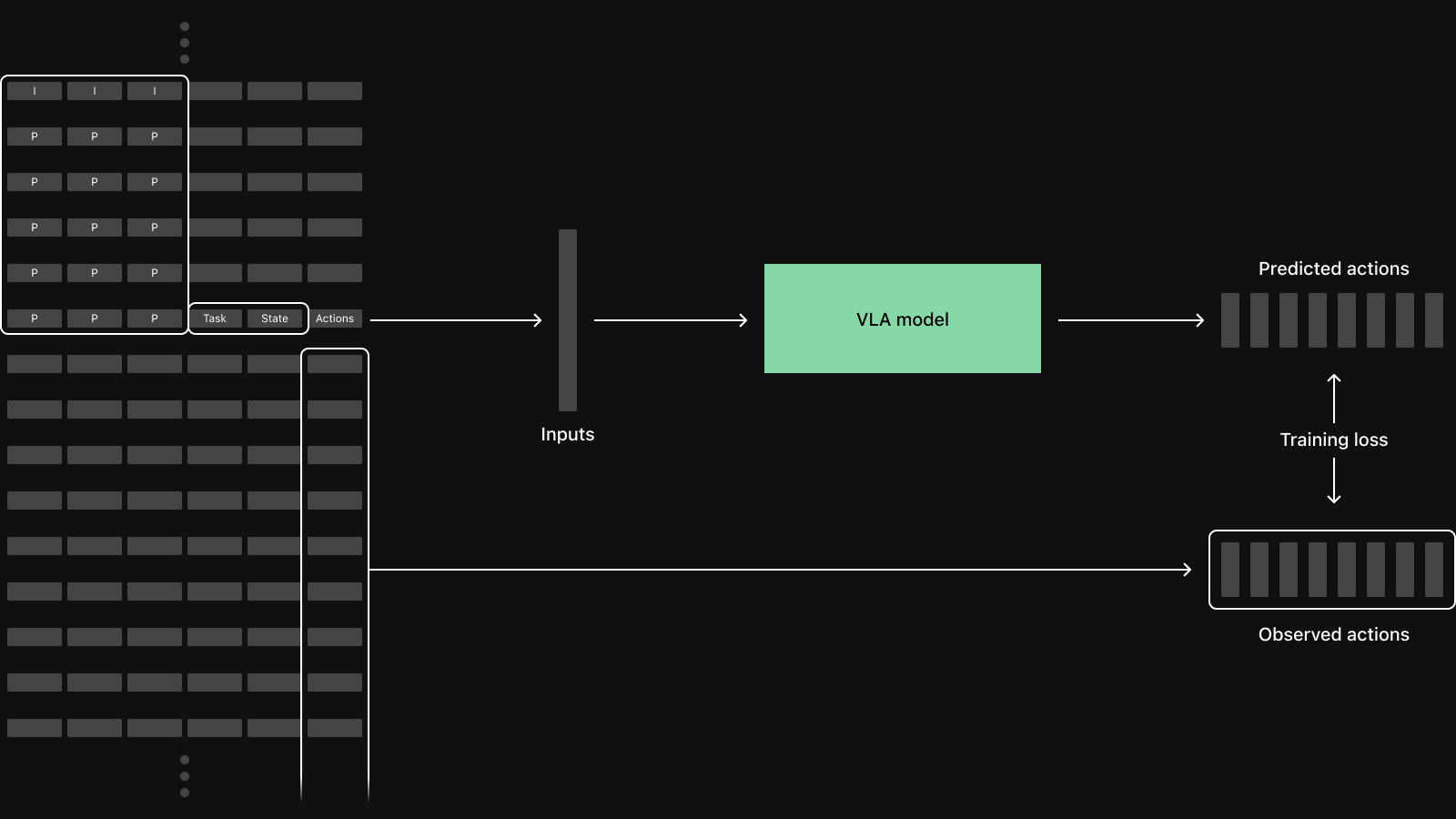
Consider training a vision-language-action model (VLA) with action chunking like ACT or pi0.5. A humanoid robot model could consume three video streams from head and wrist cameras, positions and velocities from 30+ joints, gripper states, and a language instruction.
Each training sample in a batch starts from a single time step from one of the episodes in the dataset. For a basic VLA, the sample itself consists of camera frames from each view, the robot's current state, and a chunk of future actions, often the next 50-100 time steps. Somewhere between recording on robot and training these inputs all need to be time-aligned, which is a common source of subtle bugs.
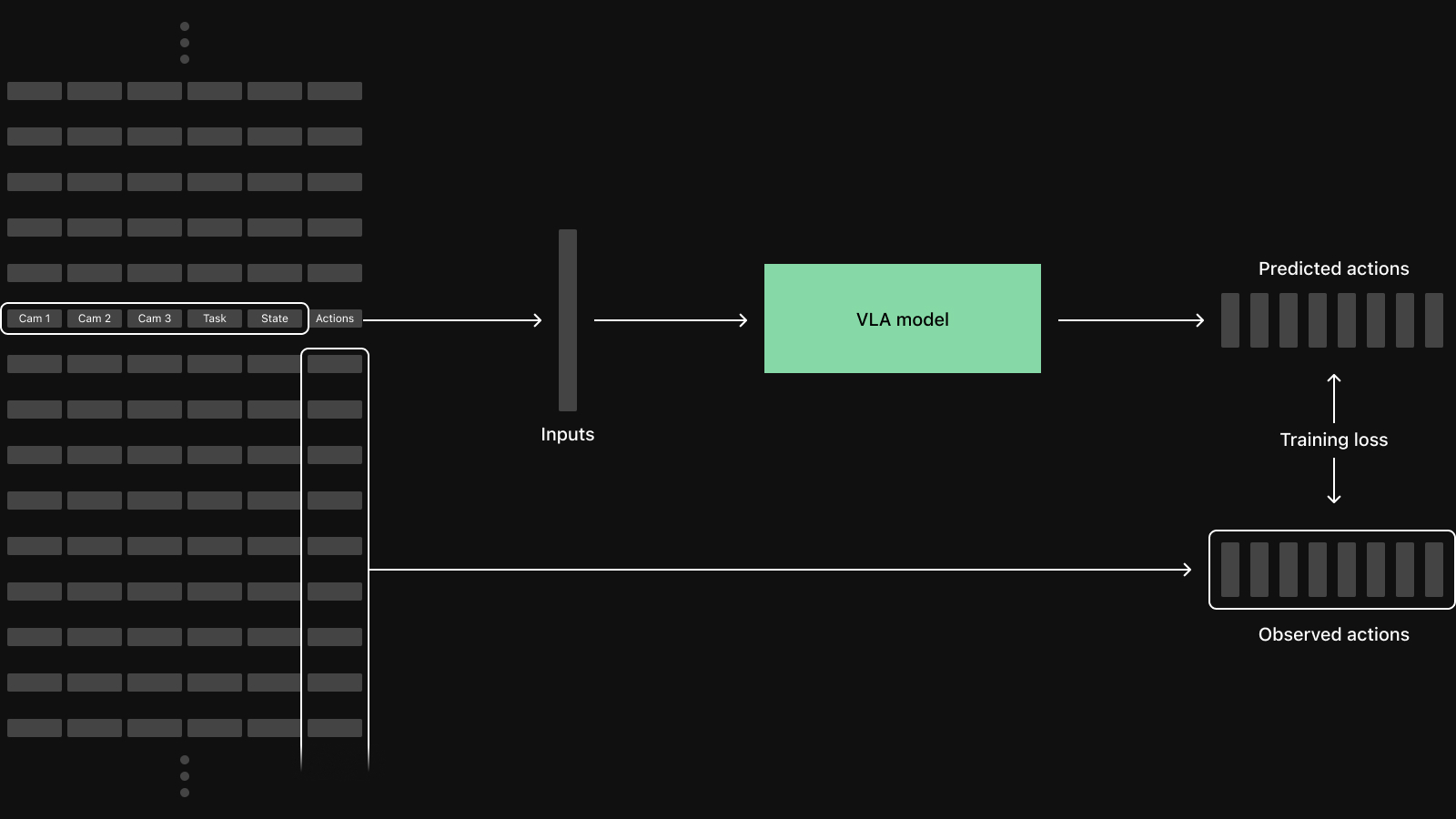
In this case, a naive row-oriented fetch that reads all columns for all time steps would download many items that are never used. An efficient dataloader needs to be column-aware: fetch full rows when needed and fetch specific columns for a time window otherwise. When the datasets are too large to live on the machine performing training this unnecessary data transfer leads to GPU starvation.
The sampling pattern depends on the architecture and will continue to evolve. Diffusion Policy conditions on 2 observation frames and predicts 16 future steps. For longer horizon tasks models often take longer history, potentially at non-uniform intervals. World Action Models (WAMs) like DreamZero consume contiguous sequences of equally spaced frames and jointly predict both future video and actions.
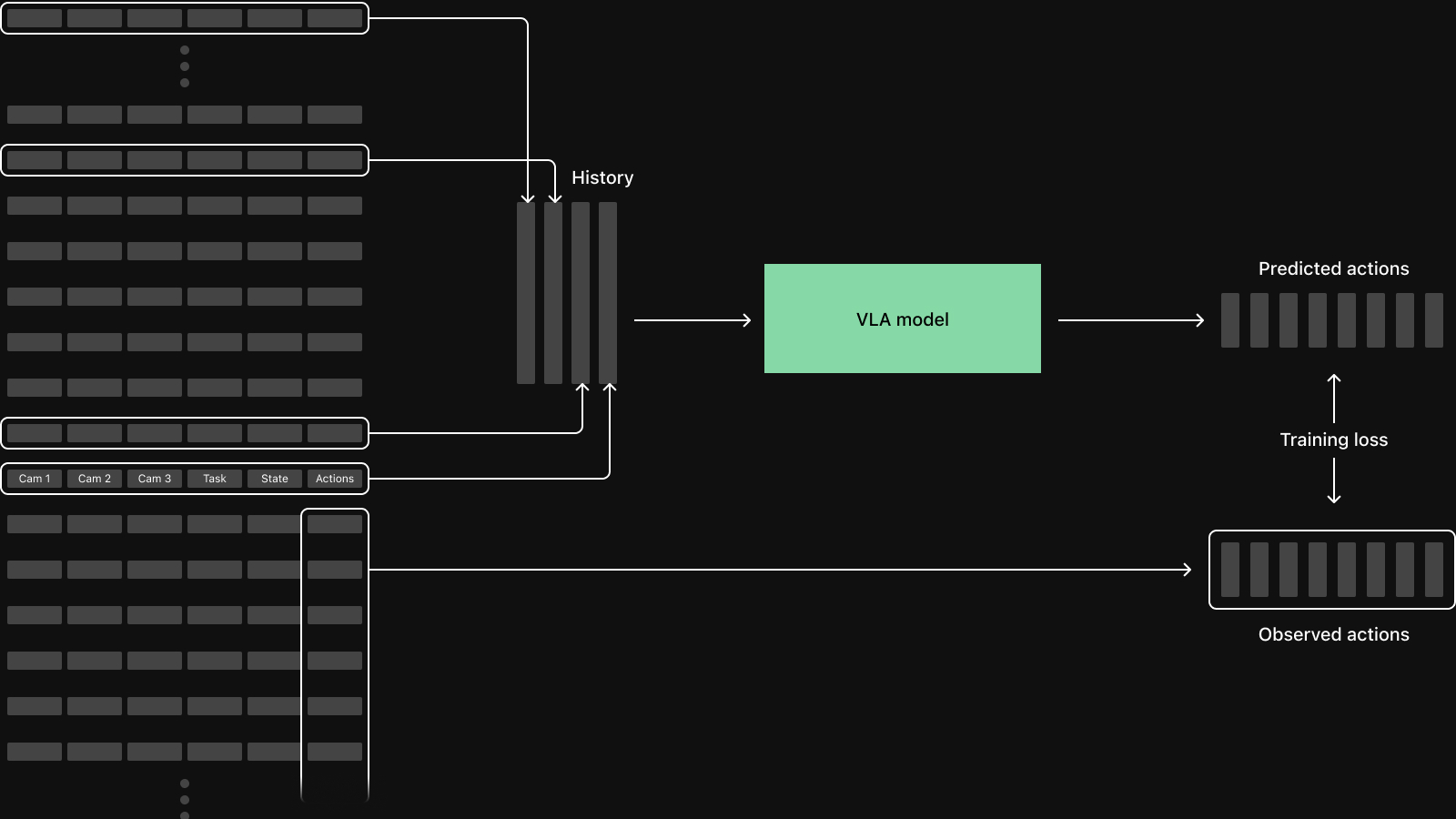
These architectures will continue to evolve but we'll always be combining multiple data streams to consider what sensors and what time points are relevant for a single observation. More complex sampling patterns also increase the risk of subtle bugs, like accidentally including actions from a different episode, that quietly degrade model performance.
Decoding video during training
Video often accounts for 90% or more of the total dataset size. Encoding images as video saves significant storage by exploiting temporal redundancy, at the expense of added complexity.
Most video codecs don't store each frame independently. They exploit temporal redundancy through a Group of Pictures (GOP) structure. A GOP starts with a keyframe which is a complete image. The following frames are delta frames that store changes relative to other frames. Delta frames are small which allows the compression.
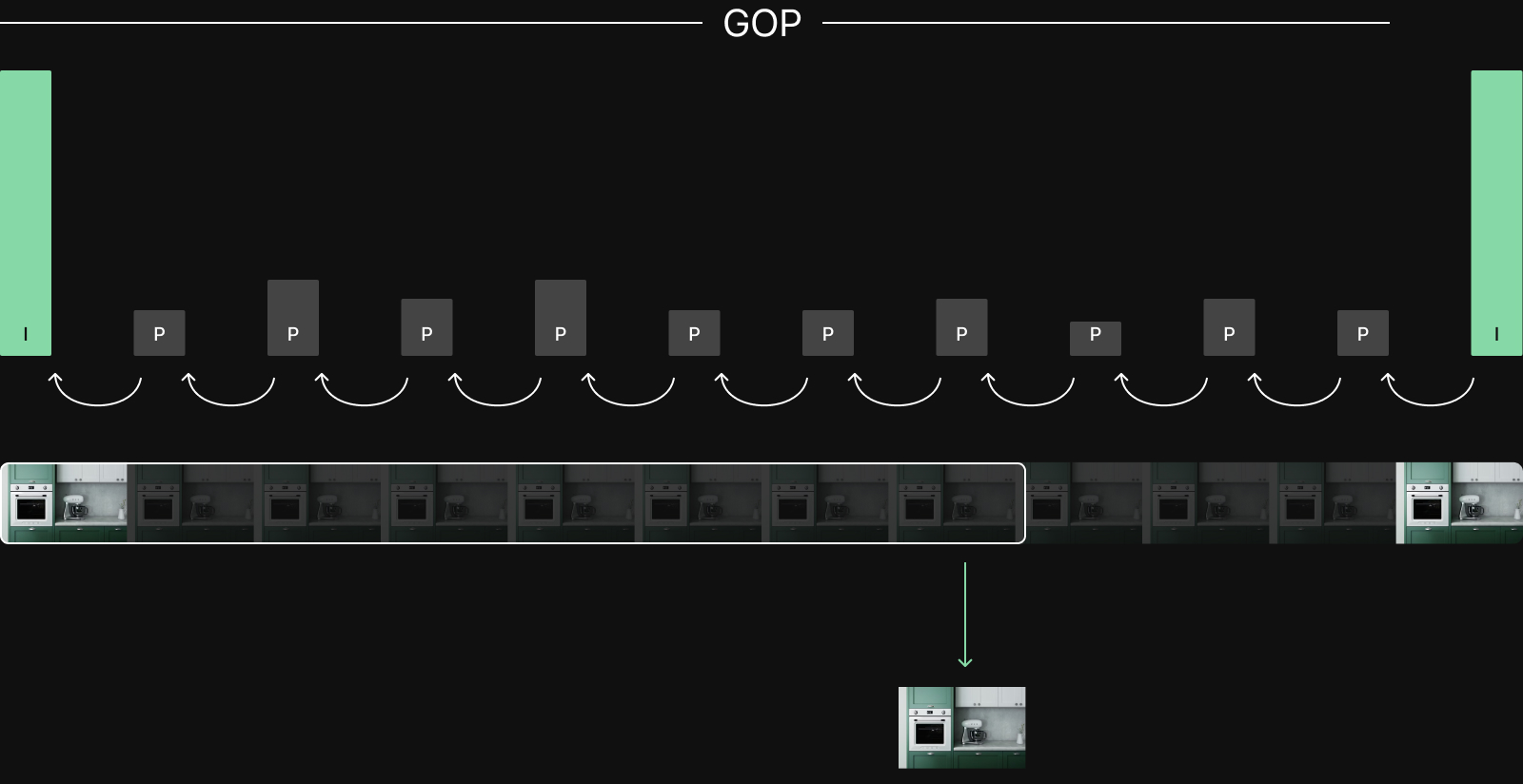
This has a direct consequence for training since models require full image frames. To decode any delta frame, the decoder must start from the nearest preceding keyframe and decode every frame in between. With a typical GOP of 30 frames, random access to a single frame requires decoding an average of 15 frames to produce 1 usable frame.
The key tradeoff is GOP size. Larger GOPs give better compression, but smaller GOPs give faster random access. LeRobot uses a default GOP of 2, making every other frame a keyframe to prioritize random access, but sacrificing potential compression.
To make things concrete, a policy with non-uniform history like current frame, previous frame, 0.5s ago, and 1s ago, across 3 cameras needs 12 frame decodes per sample (4 history frames times 3 cameras). The non-uniform spacing means these frames may land in different GOPs, each requiring a separate seek-and-decode. Either way, data fetching logic needs to handle video, either by being GOP-aware or by fetching whole video files.
Dataloader complexity translates to slower iteration speed
Building a fast and correct dataloader is difficult and gets even harder for large datasets that don’t fit on the training cluster. At the same time very few teams will accept poor GPU utilization, which means they will give up flexibility and introduce slow data export jobs to avoid starving their GPUs. Long wait times and lack of flexibility here directly impacts researchers' ability to quickly experiment with hyperparameters and what data to train, which makes dataset curation and generally improving the model harder.
Dataset curation
Getting data to GPUs fast matters, but it also needs to be the right data. Curation ensures the dataset has the right distribution to optimize model performance. HuggingFace's recent robot folding project found that curating 1,200 episodes from a pool of 5,688 moved success rates by 50 percentage points, while algorithmic improvements moved them by 5–20. However, systematically improving data composition is hard because validating improvement is slow.
Data quality
Real data is full of missing sensor streams, schema mismatches, and gaps in recordings. The QoQ paper found that 33.5% of sampled pen and pencil trajectories in the DROID dataset were outright failures. Trajectory analysis like jerkiness, speed distributions, and gripper activity can filter further and are easy to write; provided the right data interface. When robot data is spread across video streams, joint state logs, and action recordings at different rates, even this simple analysis can be difficult.
Most teams also do significant visual review. Looking at lots of data is the best way to catch novel issues and build intuition. For robotics that means both rapid browsing and deep dives into multimodal recordings.
Learned models offer more powerful analysis. Reward models like SARM, originally trained to score task progress, can also be used to score data quality, and methods like DemInf estimate each trajectory's contribution to the dataset's state-action mutual information. These are more expensive to run, but aim to scale better than human review.
Beyond filtering, one of the highest-impact quality improvements is improving data collection. Researchers who regularly review data notice that operators hesitate in certain situations, camera angles create ambiguity, or that gripper approaches are inconsistent. Improving the collection setup improves data quality more than any amount of downstream filtering.
Dataset mixing
Dataset composition has a large impact on performance: which datasets to include, how to weight different task-robot combinations, and what to emphasize or deemphasize. Physical Intelligence's pi0 was pre-trained on a mix of their own teleop data, simulation, and open datasets, with each task-robot combination weighted by a power law that down-weights over-represented combinations. This CoRL 2024 Best Paper showed that after a baseline number of demonstrations per task, adding task diversity matters far more than adding more demonstrations. How you compose the mix can matter more than how much data you have.
Simulation sharpens this problem. Sim data is cheap to generate, so it can easily dominate a training mix. But the sim-to-real gap means more sim data isn't always better, and getting the ratio right requires experimenting with dataset composition.
Training-time metrics like loss curves and proxy benchmarks can give useful signal on whether a mix is working, even before real-world evaluation. Teams could iterate on dataset composition relatively quickly, but with an inflexible dataloader, each new mix requires filtering and combining datasets offline, exporting a new copy, and pointing training at it. That overhead adds friction to every iteration, and discourages systematic experimentation.
Ideally, dataset mixing would be expressed as a query: which datasets, what weights, what filters. The training dataloader would serve samples without a separate materialization step, and trying a new variant would be a parameter change rather than a pipeline run and dataset copy.
Enhancing with annotations and post-processing
For basic teleoperation data, processing between recording and training is relatively modest. Teams add task annotations, compute time-aligned state and action columns at the target training frequency, and run the quality checks described above. Time alignment is easy to get wrong, which can significantly degrade training, but the operations themselves are well-defined. Running the more powerful curation methods from the previous section, like reward models or generating embedding vectors, requires significant compute to produce derived data that needs to be integrated.
As teams scale and look beyond teleop data, something ironic happens. End-to-end models simplify the perception stack, but they demand so much training data that teams are forced to look to cheaper and more scalable sources.
): real-world robot data at the top, synthetic data in the middle, and web data and human videos forming the broad base.](/blog/data-layer-tax/data-pyramid.jpg)
Companies like Sunday Robotics and Generalist AI use human data collectors wearing UMI-style grippers to generate demonstrations faster and cheaper than with real robots. Turning that data into something trainable requires extracting 3D gripper poses from camera feeds using SLAM, retargeting human motions to robot kinematics, and validating spatial consistency. Generalist AI reports using 10K+ CPU cores for these pipelines. The complexity didn't disappear. It moved from robot inference to the data pipeline.

Pure egocentric video from head-mounted cameras requires even more processing since the motions being recorded are human hands, not grippers, and the camera viewpoint needs to be mapped to the robot's perspective.
Teams also use 3D reconstruction to augment existing datasets. Tesla uses proprietary Generative Gaussian Splatting to reconstruct full 3D scenes from multiple camera views, enabling synthetic variations of real-world recordings for both FSD and Optimus.
All of this processing reads source data, computes derived signals, and writes results back at potentially different temporal rates from the source. The complexity that end-to-end learning removed from the robot is reappearing here, in the data pipeline. If the data layer can't natively model and store multi-rate and multimodal data, managing and debugging these pipelines quickly grows in complexity.
Recording, ingesting, and normalizing
Every robot and collection setup is different, so teams inevitably build custom solutions. Teleoperation is tightly coupled to the specific robot since low-latency control demands direct hardware integration. Cloud inference or live reinforcement learning have a completely different recording architecture where data may never touch the robot's local storage at all. Building these systems well matters because they determine what data you have to work with downstream.
The challenge starts at ingestion: normalizing all of this into something that can be worked with. Even within a single team using a single recording format, schemas shift over time. A new sensor gets added, joint naming conventions change, the recording software gets updated and fields move around. Data collected six months ago may have a structure than data collected today, and both need to work together for training.
At larger scale, teams combine data from multiple robot configurations, each with their own conventions. Open X-Embodiment required 60+ custom dataset conversion builders contributed by different labs. Converting a large dataset like DROID between formats can take days.
Getting all of this into a common queryable form is what makes every downstream step possible. Brittle pipelines are particularly painful when debugging across the stack. You find something off in evaluation, trace it back through training and curation, and eventually realize the issue is how source data was ingested. Teams need a framework for this data wrangling and a common format that makes it easy to bring in new data without breaking what is already there.
A tradeoff with precedent
In analytics, teams spent years maintaining separate systems for different consumers of the same data. Data lakes stored everything cheaply in open formats, but lacked the structure for reliable querying. Data warehouses offered fast, structured queries, but required rigid schemas and locked data into proprietary formats that ML tools couldn't read. So teams ran both, ETL'd data between them, and often exported again for ML workloads, creating multiple copies with different schemas, different freshness, and brittle pipelines connecting them. The lakehouse architecture resolved this by adding a structured metadata layer (transactions, schema enforcement, indexing) directly over open file formats on object storage. One copy of the data, accessible to BI, analytics, and ML without separate systems or redundant ETL.
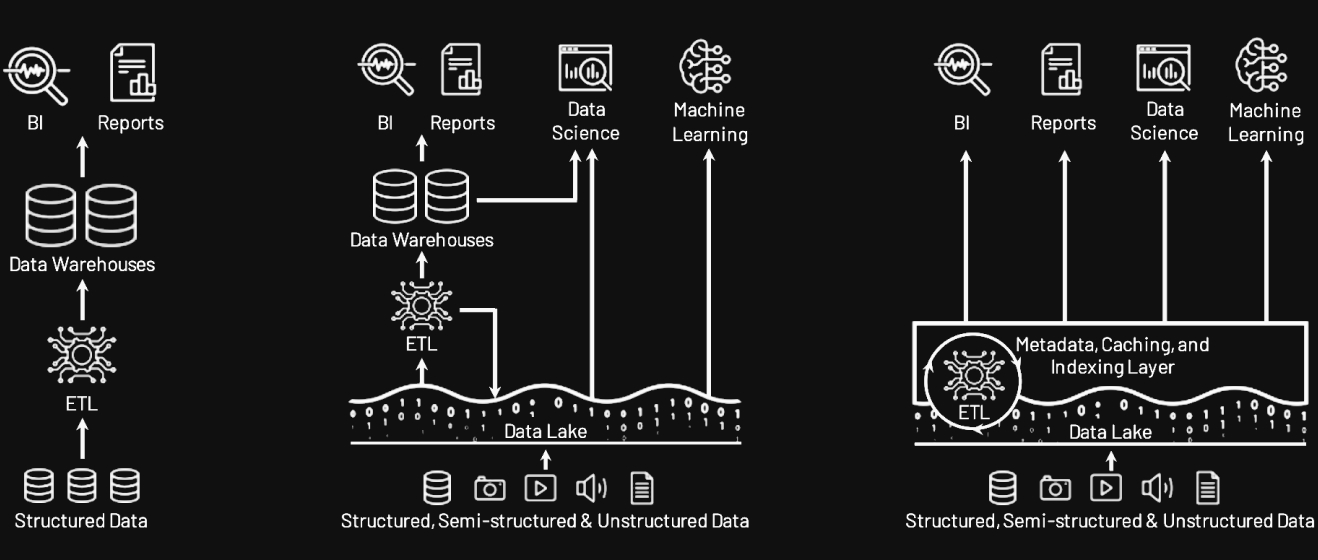
Robotics data infrastructure is stuck in its own version of this tradeoff. File-based processing on log formats like MCAP is great for recording and replay but impractical for large-scale querying and training. Early normalization into fixed schemas like LeRobot gets you training fast but locks in decisions that are expensive to change. Table-per-topic approaches borrowed from analytics allow late normalization but explode in complexity when multiple systems need to join them back together. Teams end up maintaining multiple representations of the same data with conversion pipelines between them.
On top of this, Physical AI data needs to be visually inspectable at every stage. Researchers build intuition by watching trajectories, not reading tables. If the data layer doesn't serve visualization natively, it becomes yet another consumer with its own format requirements and its own conversion pipeline.
Each approach solves one part of the problem and creates friction everywhere else. That friction compounds as teams scale dataset sizes, source variety, and curation sophistication.
The data layer tax
The most visible cost of an immature data layer is the engineering time spent on format conversion, custom loaders, and pipeline glue. But the real cost is the work that never happens. It's the dataset mixes that are too slow to try because each one requires a full data export rather than a parameter change. It's the curation methods that can't be applied at scale because the data isn't queryable. It's the transform bugs that ship to training unnoticed because visualization was only built for the recording stage. It's the eval failure that takes days to trace back to a collection issue because the tools are disconnected. Doing research on the wrong foundations feels like walking in mud in the dark.
In robot learning, you build adaptable and reliable models by closing loops. Record, analyze, train, deploy. The winning teams will run these loops faster and with more precision than the rest. They won't do it on a data layer that charges a heavy tax for every move.
At Rerun we've spent the last years building the pieces needed to solve this from first principles. We are getting ready to share it with the world. If you recognize the problems in this post and want to learn more, reach out.