Image and video understanding
PaddleOCR
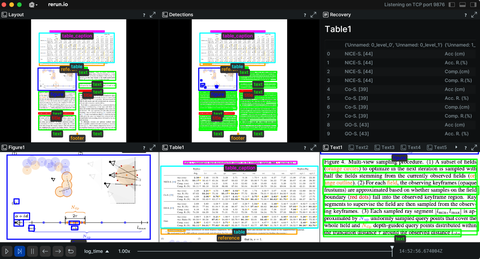
This example visualizes layout analysis and text detection of documents using PaddleOCR.
Used Rerun types
Image, TextDocument, Boxes2D, AnnotationContext
Background
This example demonstrates the ability to visualize and verify the document layout analysis and text detection using the PaddleOCR. PP-Structure used for this task, which is an intelligent document analysis system developed by the PaddleOCR team, which aims to help developers better complete tasks related to document understanding such as layout analysis and table recognition. In the layout analysis task, the image first goes through the layout analysis model to divide the image into different areas such as text, table, figure and more, and then analyze these areas separately. The classification of layouts and the text detection (including confidence levels) are visualized in the Rerun viewer. Finally, the recovery text document section presents the restored document with sorted order. By clicking on the restored text, the text area will be highlighted.
Logging and visualizing with Rerun
The visualizations in this example were created with the following Rerun code.
Image
The input document is logged as Image object to the {page_path}/Image entity.
rr.log(f"{page_path}/Image", rr.Image(image_rgb))Label mapping
An annotation context is logged with a class ID and a color assigned per layout type using AnnotationContext.
class LayoutType(Enum):
UNKNOWN = (0, "unknown", Color.Purple)
TITLE = (1, "title", Color.Red)
TEXT = (2, "text", Color.Green)
FIGURE = (3, "figure", Color.Blue)
FIGURE_CAPTION = (4, "figure_caption", Color.Yellow)
TABLE = (5, "table", Color.Cyan)
TABLE_CAPTION = (6, "table_caption", Color.Magenta)
REFERENCE = (7, "reference", Color.Purple)
FOOTER = (8, "footer", Color.Orange)
@property
def number(self):
return self.value[0] # Returns the numerical identifier
@property
def type(self):
return self.value[1] # Returns the type
@property
def color(self):
return self.value[2] # Returns the color
@classmethod
def get_annotation(cls):
return [(layout.number, layout.type, layout.color) for layout in cls]
def detect_and_log_layout(img_path):
rr.log(
f"{page_path}/Image",
# The annotation is defined in the Layout class based on its properties
rr.AnnotationContext(LayoutType.get_annotation()),
static=True,
)Detections
The detections include the layout types and the text detections. Both of them are logged as Boxes2D to Rerun.
rr.log(
base_path,
rr.Boxes2D(
array=record["bounding_box"],
array_format=rr.Box2DFormat.XYXY,
labels=[str(layout_type.type)],
class_ids=[str(layout_type.number)],
),
rr.AnyValues(name=record_name),
)Additionally, in the detection of the text, the detection id and the confidence are specified.
rr.log(
f"{base_path}/Detections/{detection['id']}",
rr.Boxes2D(array=detection["box"], array_format=rr.Box2DFormat.XYXY, class_ids=[str(layout_type.number)]),
rr.AnyValues(DetectionID=detection["id"], Text=detection["text"], Confidence=detection["confidence"]),
)Setting up the blueprint
Blueprint sets up the Rerun Viewer's layout. In this example, we set the layout for the layout classification, the Detections for the text detection and the Recovery for the restored detections, which includes both layout analysis and text detections. We dynamically set the tabs, as there will be different tabs for figures, tables and text detection.
The blueprint for this example is created by the following code:
page_tabs.append(
rrb.Vertical(
rrb.Horizontal(
rrb.Spatial2DView(
name="Layout",
origin=f"{page_path}/Image/",
contents=[f"{page_path}/Image/**"] + detections_paths,
),
rrb.Spatial2DView(name="Detections", contents=[f"{page_path}/Image/**"]),
rrb.TextDocumentView(name="Recovery", contents=f"{page_path}/Recovery"),
),
rrb.Horizontal(*section_tabs),
name=page_path,
row_shares=[4, 3],
)
)
# …
rr.send_blueprint(
rrb.Blueprint(
rrb.Tabs(*page_tabs),
collapse_panels=True,
)
)Run the code
You can view this example live on Huggingface spaces.To run this example locally, make sure you have the Rerun repository checked out and the latest SDK installed:
pip install --upgrade rerun-sdk # install the latest Rerun SDK
git clone git@github.com:rerun-io/rerun.git # Clone the repository
cd rerunInstall the necessary libraries specified in the requirements file:
pip install -e examples/python/ocrTo experiment with the provided example, simply execute the main Python script:
python -m ocr # run the exampleIf you wish to customize it, explore additional features, or save it use the CLI with the --help option for guidance:
python -m ocr --helpDepending on your system, pip may grab suboptimal packages, causing slow runtimes.
Installing with Pixi has been observed to run significantly faster in this case and it will automatically install poppler which is required to run the example on PDF files.
To do so, simply run these commands after checking out the repository and installing Pixi:
pixi run py-build && pixi run uv run examples/python/ocr/ocr.py