Sharing in Rerun - from web to native viewer
Open by design
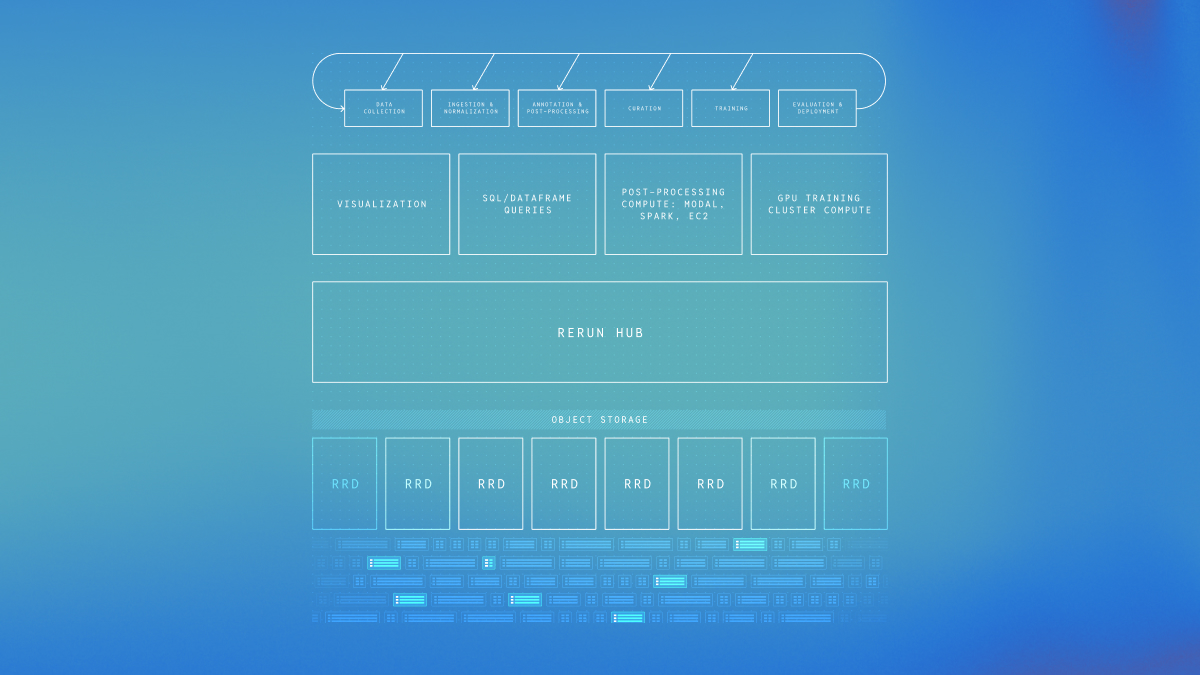
Physical AI systems generate massive amounts of multimodal data (sensor readings, camera feeds, point clouds, trajectory data) that need to be analyzed, debugged, and shared across distributed teams. Yet most visualization tools treat sharing as an afterthought, creating friction exactly where collaboration matters most.
At Rerun, we believe that effective Physical AI development requires teams to see and use physical AI data. Seeing might mean simply getting access to the right visualization, the right episode, or curating the right dataset for training.
As part of release 0.25, we've rounded out some sharing capabilities that we wanted to write a bit more about.
Building in the open
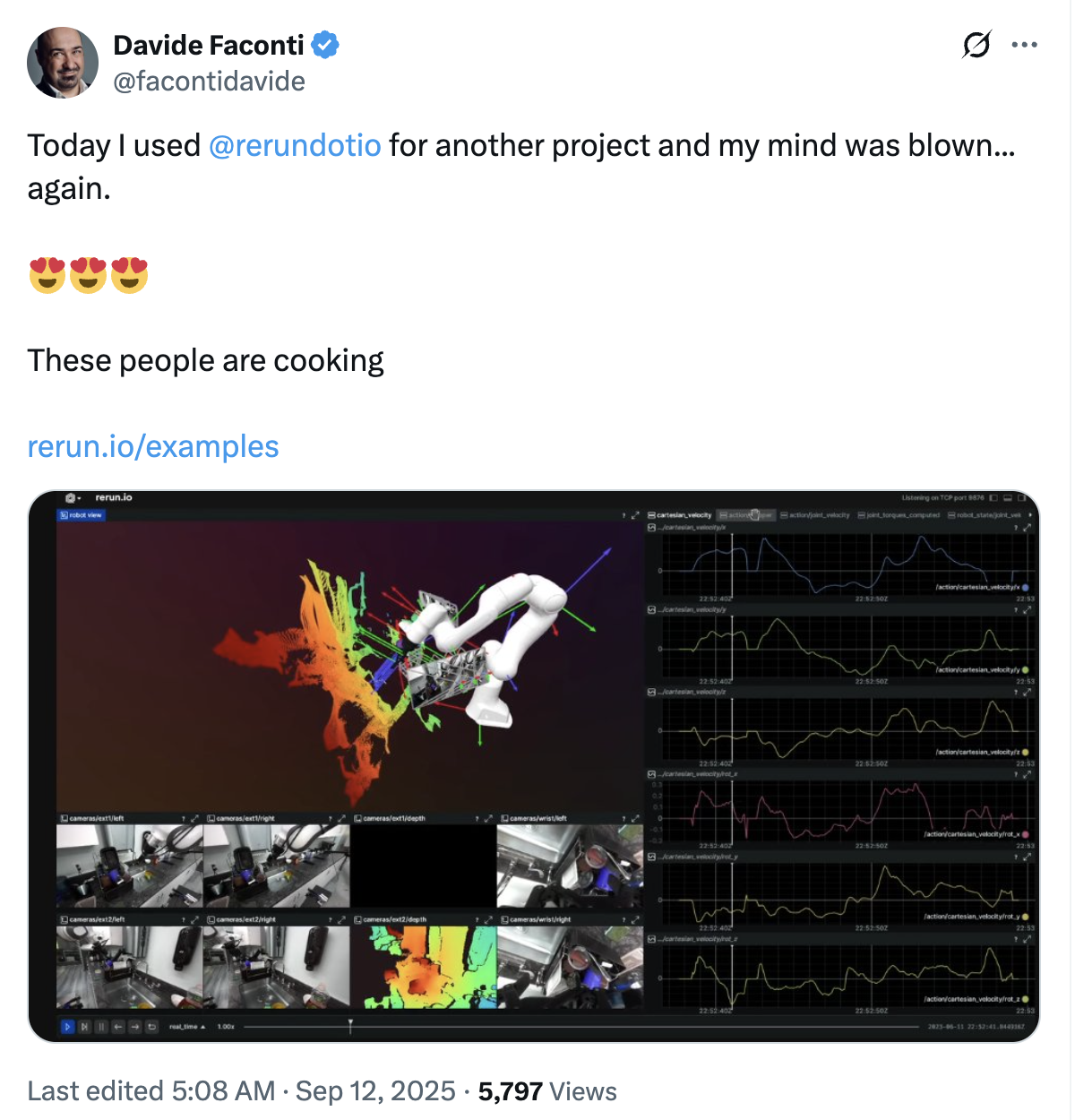
It should go without saying, but by making Rerun open source, we're prioritizing building in the open. We are proud of the progress that we've made with widespread adoption from robotics teams large and small. Companies like Meta, Google, Hugging Face's LeRobot, and Unitree have adopted it in their own open-source work.
While the Viewer is open source, an important aspect of 'building in the open' is not just about code but also about sharing. In Rerun, every stored 'episode' is a URL (ok... technically a URI). That makes it addressable.
You can see that with our examples (which are just episodes), that are just a click away.
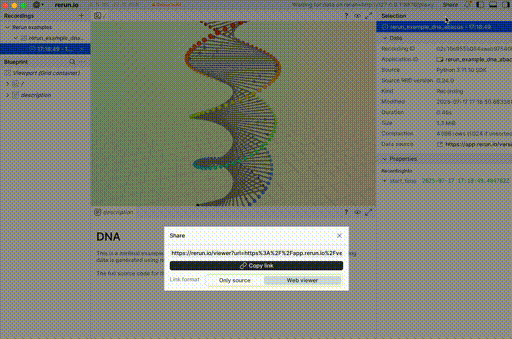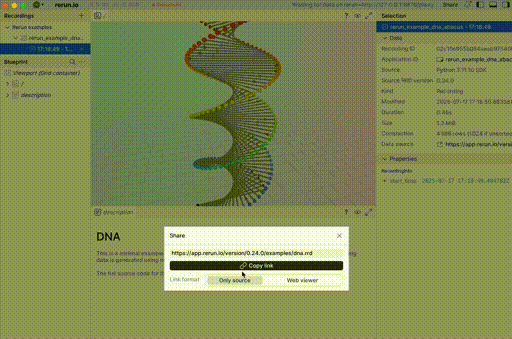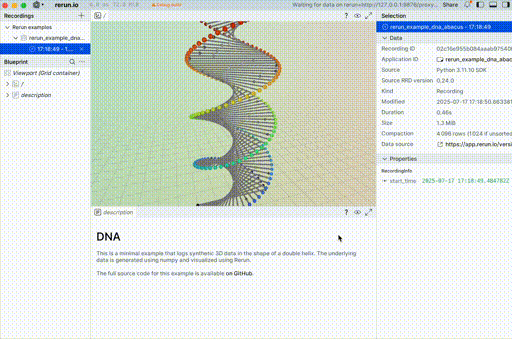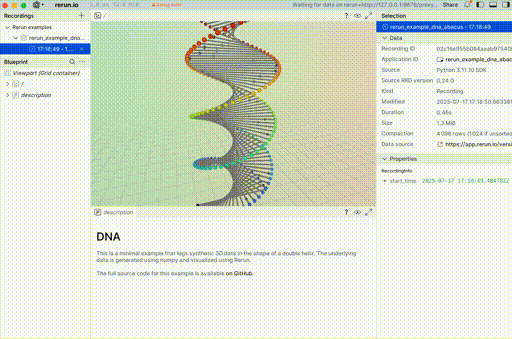
You can see that with what people share across the web as well.

Image courtesy Valstad Shipworks
Visualization is to Physical AI data what print is to text and so we believe strongly, it needs to be open source and everywhere.
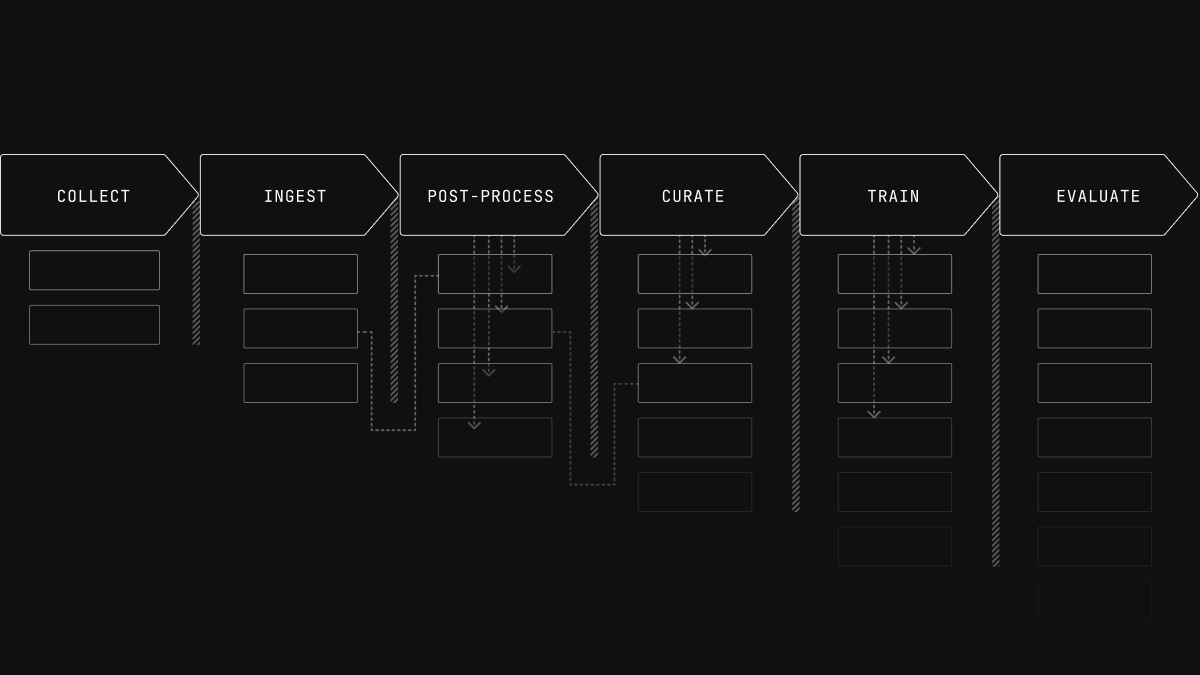
Sharing episodes in Rerun
Over the past months, we've introduced some features that make sharing that much easier. This is just the start, but we felt that it would be good to review all of the new capabilities (as of Rerun 0.25) for those just getting started.
Open recordings from the viewer
Hit CTRL/CMD + SHIFT + L and paste a Rerun link and you're 'in' that episode! The same applies for examples across the web!
Open recordings from the CLI
Our CLI makes link opening a native operation. Whether you're processing datasets in a batch job on Rerun Hub or debugging a specific recording, sharing is as simple as passing a URL:
# Any of these work instantly
rerun path/to/data.rrd
rerun https://storage.googleapis.com/bucket/dataset.rrd
rerun https://lab.rerun-cloud-url.rerun.io/?url=...This integration means your automation pipelines, CI/CD systems, and analysis scripts can generate shareable visualizations for your whole team.
Open from the viewer
Power users shouldn't need to leave their keyboard. CTRL/CMD + P opens the command palette where you can instantly import any link.
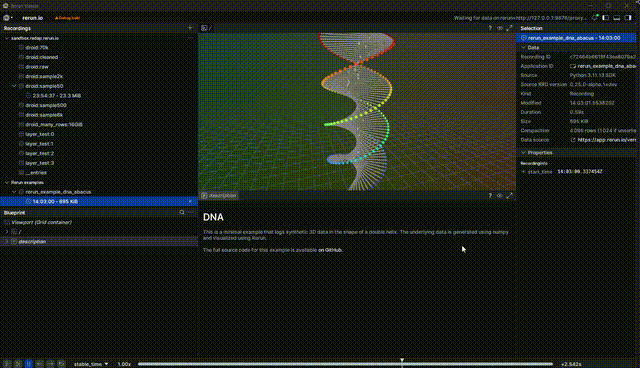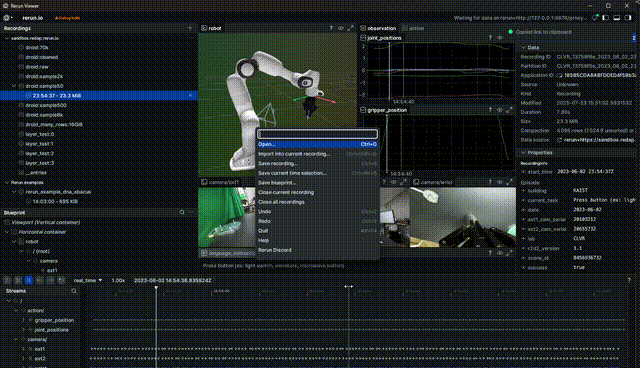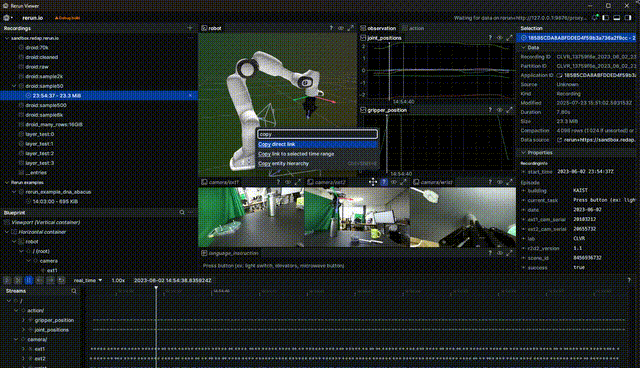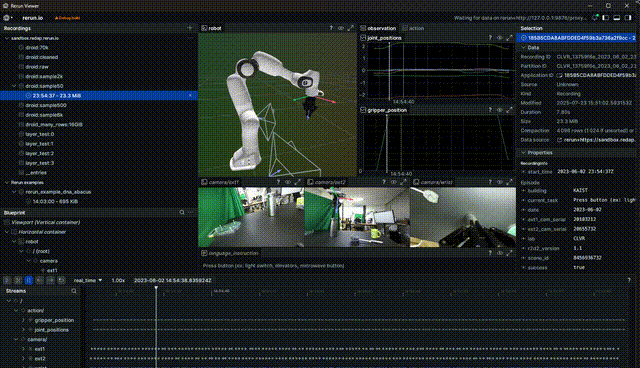
Getting a link to share
To get a link, you can either hit "Share" from the top right corner menu or use the CTRL/CMD + P shortcut to open the command palette and get a link.
Why is sharing so critical and why it should be open source
These sharing capabilities are critical. As we talked about earlier this year,
visualization gets built into core tools throughout your codebase. Depending on a single closed source vendor for that is a huge risk. If you also want that visualization to be low friction, consistent, and possible to extend, the only real option is open source or maintaining an in-house implementation.
That's one of the reasons that the LeRobot team chose Rerun for their visualization capabilities - it's simple, open, and collaborative.
Rerun Hub
While we're not quite ready to share many details yet, we're prioritizing even more collaboration inside of Rerun Hub - allowing users to share visualizations (and data) with the people that need it most.
Rerun Hub is under development with select design partners. If you're interested in getting your hands on an early version you can get in touch.
A connected ecosystem (and future)
Easy sharing accelerates Physical AI development in ways that aren't immediately obvious. When a robotics engineer can instantly share a sensor fusion visualization with a machine learning researcher, when a field technician can send a malfunction recording directly to the development team, when academic collaborators can access the same data view regardless of their platform, these small frictions removed compound into major productivity gains.
Physical AI is inherently collaborative. The tools that support it should be too. By designing sharing into our core architecture and keeping it open source, we're building infrastructure for an ecosystem where physical data can flow as freely as the insights it contains!