The Missing Data Infrastructure for Physical AI
Most of the world's GDP exists in the physical world, creating an enormous opportunity for Physical AI to transform our economy. We started Rerun with the thesis that computer vision and robotics were about to transform the world around us but the rate of progress over the last two years has been far greater than any of us could have imagined.
We’re excited to announce that Rerun has raised $17 million in seed funding to build out the data stack for Physical AI. The round is led by Point Nine, with participation from Costanoa, Sunflower Capital, Seedcamp, and notable angels including Guillermo Rauch, Eric Jang, Oliver Cameron, Wes McKinney, and Nicolas Dessaigne.
We spent the past 2 years building the most popular open source framework for logging and visualizing multimodal data. Today, companies like Meta, Google, Hugging Face’s LeRobot, and Unitree have adopted it in their own open-source work. We’re continuing that work by building a new database and cloud data platform for Physical AI that will help teams run more experiments faster.
Physical AI has gone from intractable to inevitable
Physical AI, whether it's autonomous vehicles, robots, drones, or spatial computing, has traditionally been a hard category to build and invest in. To sell complex hardware at mass market prices you need high volumes to justify your large upfront costs. At the same time it’s been hard to build general enough intelligence into these systems to address large markets.
The massive progress in AI over the last years has changed that equation and instead kicked off a flywheel that is hard to stop. AI progress drives investment, which leads to more and better deployed hardware that collects more data. That in turn drives AI progress even further which expands the addressable market.
Machine learning moves complexity from online to offline data pipelines
To deliver a Physical AI product you need two kinds of systems; online systems, which are what runs live on the robot as it moves through the world, and offline systems that run in a data center in service of analyzing or improving the online systems.
In classic robotics systems, intelligent behavior is hand-written and the bulk of complexity lies in online systems. Offline data systems mainly handle evaluating and testing the online code on recorded data or simulations.
Since the mid 2010s, when deep learning started to work for simpler tasks, teams have been steadily replacing online system code with trained models. The trend continues today with larger and larger tasks being trained end-to-end. Companies like Tesla and Wayve train models that take video and raw sensor values as input and output gas, break and steering controls directly.
Machine learning can radically improve systems’ capabilities but it requires complex offline data pipelines. You need to collect, manage, and curate large datasets and figure out how to best train models on that data. The larger and more complex tasks the models solve, the more complex the offline data curation. For example, teams might run larger models offline that 3D reconstruct the full robot environment and auto label recordings. Those labels are used to improve training of a model that is then deployed for online inference.
Using different stacks for online and offline data results in friction
Traditional data tools for robotics, like RViz and its descendants, were designed for the era before machine learning. They provide observability through visualization of logs from online systems, but aren’t built for the large scale offline data processing needs of modern Physical AI.
On the other hand, data lake and lakehouse architectures like e.g. Databricks, are built for large scale analytics and machine learning but don’t natively understand Physical AI data, which often contains spatial relationships that change over time. Imagine trying to fit the evolving state of a multiplayer 3D game into a table of numbers and strings.
Once data has been extracted from the raw online logs for further offline processing, the semantic information about what the data really means is lost. Traditional robotics visualizers then no longer work, which means researchers lose visibility into the whole data pipeline. The loss of semantics also forces researchers to write lots of translation code to reinterpret the data at each step.
All this complexity hurts iteration speed and velocity.
Rapid progress requires fast, observable, low-friction infrastructure
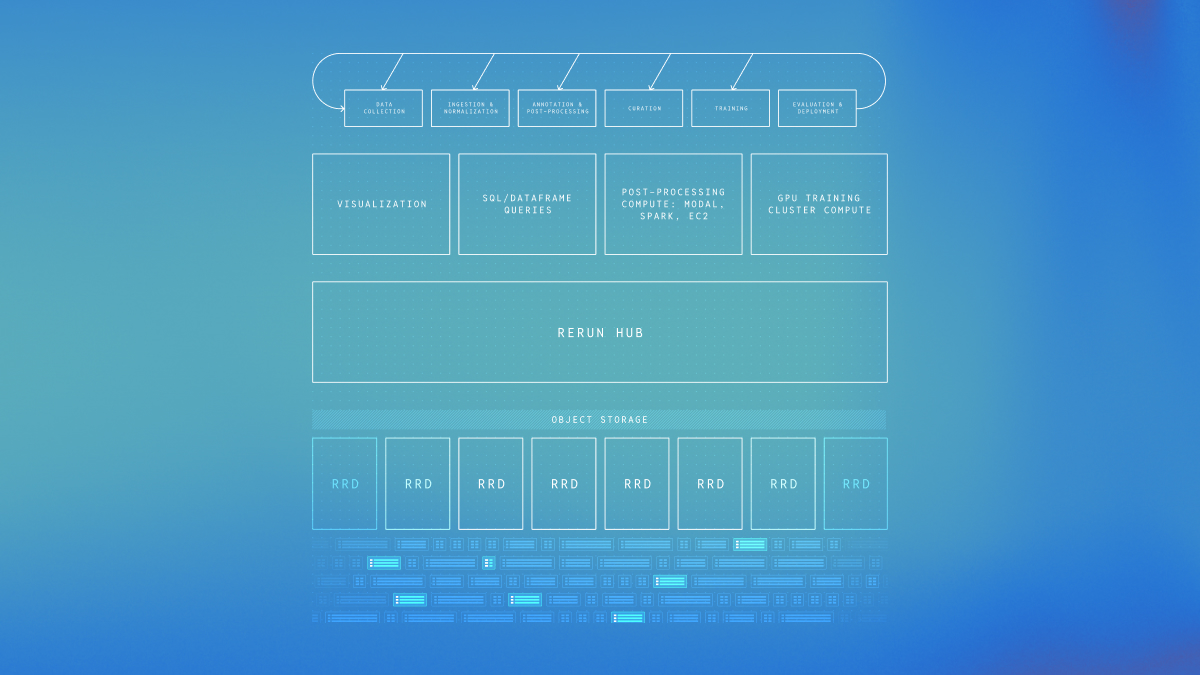
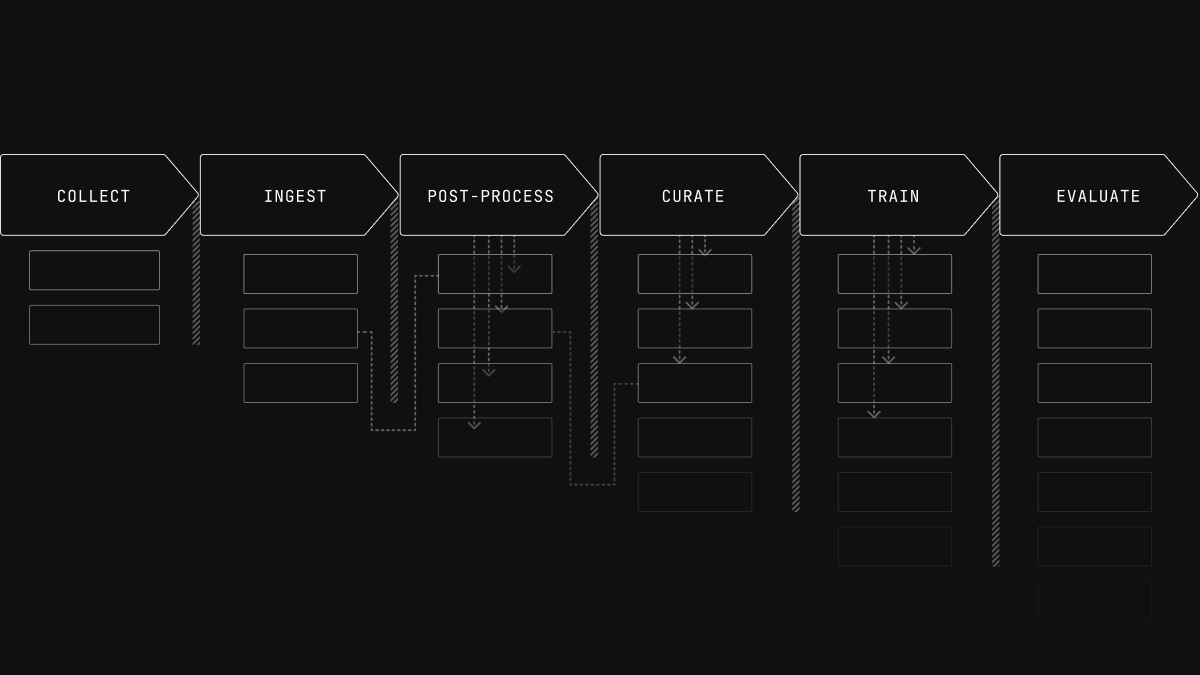
To rapidly progress in AI capabilities, what matters most is running high quality experiments fast. To do that, researchers need data infrastructure that is fast, flexible, simple to use, and easy to modify. To generate new ideas and spot problems early they also need observability of their data all the way from collection, to enhancement, training, and evaluation.
Researchers should be able to work with raw logs as well as cleaned training data in a consistent way. They should be able to easily enhance a dataset with new embeddings, or jump from a training sample to the recording it came from. They should be able to directly visualize any data they have, regardless of what stage of processing it’s in. They should be able to use vector search and SQL queries to curate datasets without needing a separate system.
What’s needed is a consistent data model across online and offline data
In order to have a low-friction experience with good observability when working across the data lifecycle, you need a powerful data model that's consistent all the way through. Physical AI data is complicated; it includes things like streams of video, 3D, and other sensor data, all changing asynchronously at different rates.
A data model determines how you describe and interpret stored data. A good model is flexible enough that it can easily model the scenarios researchers care about, but constrained enough to make doing the right thing easy and performant.
With a consistent data model, it's possible to build an engine that can visualize any data in that model without extra steps, providing seamless data observability. Rerun’s open source visualization system is built in exactly this way. We spent the first 2 years of the company iterating on a data model for Physical AI that works for both messy online logs and efficient columnar storage of offline pipeline data.
The second thing a good data model for Physical AI enables, is moving more domain specific operations directly into the database layer. You can for instance perform time-alignment or resolve chains of spatial transforms as part of a database query, making analysis and curation of these kinds of datasets vastly simpler.
Visualization must be open source because it’s needed everywhere
Visualization is to Physical AI data what print is to text. It needs to be available everywhere, in all layers of the stack, for data in all forms.
Building an autonomous robot includes prototyping algorithms, training and evaluating models, testing sensors, field observability, QA, simulation, data annotation and curation, debugging data pipelines, and much more. In all these tasks visualization helps you understand what's happening. These tasks get solved in a variety of environments; from edge devices, to notebooks and scripts, to large batch jobs in the cloud, to custom tools and dashboards.
Because of this, visualization gets built into core tools throughout your codebase. Depending on a single closed source vendor for that is a huge risk. If you also want that visualization to be low friction, consistent, and possible to extend, the only real option is open source or maintaining an in-house implementation.
The query engine needs to understand datasets in multiple storage formats
Online robotics systems usually use message-oriented architectures that produce data at multiple rates. Motion sensors often send data at 1000Hz, a camera might provide new frames at 30Hz, and a high level planning model might update at 4Hz. These kinds of unaligned datasets are inefficient to store in tabular formats. In addition, these systems often need to optimize for writing the data to disk quickly with low overhead. These log recordings are therefore usually stored in MCAP, uLog, rrd, or similar custom formats.
What these formats have in common is that they are not suited for efficient large scale storage and processing. Offline systems tend to use other, usually tabular, storage formats like Parquet or Avro, together with binary files like videos. The conversion from unaligned datasets to structured tables is often lossy, requiring resampling and interpolation to align the data and make it easier to process.
To enable processing of online and offline data in a low friction and consistent way, you need storage and query engines that can read and understand both unaligned message-oriented datasets as well as aligned tabular datasets from multiple storage formats. Rerun enables this by combining a query engine that makes use of the Rerun data model with a plugin system for mapping arbitrary data sources into that model.
We’re building the missing data stack for Physical AI
Rerun is building the data stack for Physical AI. The Rerun open source project helps you model, log, and visualize Physical AI data. It will always stay permissively licensed. We’ll use the new funding to both improve the open source project, and to build a new database and cloud data platform around it.
The database is built around the same data model as the open source project. This means it comes with visualization built-in to give teams fast data observability over both online and offline systems. The query engine enables you to seamlessly combine vector search and full dataframe queries, over both raw logs and structured datasets, to support robotics-aware data science and dataset curation.
Most importantly, Rerun lets you experiment, iterate, and ship Physical AI products faster.
The data platform is currently under development with select design partners, and if you’re interested in getting your hands on an early version you can get in touch here. If you find Rerun's vision exciting, and would like to help us build it, we have open roles across the company.