A new data layer for robot learning
Physical AI will reshape industries across the physical world, but robotics still lacks the unified data layer needed to iterate at the speed modern AI demands. The core challenge is that robot learning operates on physical data: multimodal, multi-rate streams tied to time, space, and embodiment. Existing infrastructure was largely built around web data and struggles with these properties.
At Rerun we're building a unified data layer for physical data to help teams train and ship intelligence for the real world.
Rerun's biggest release yet
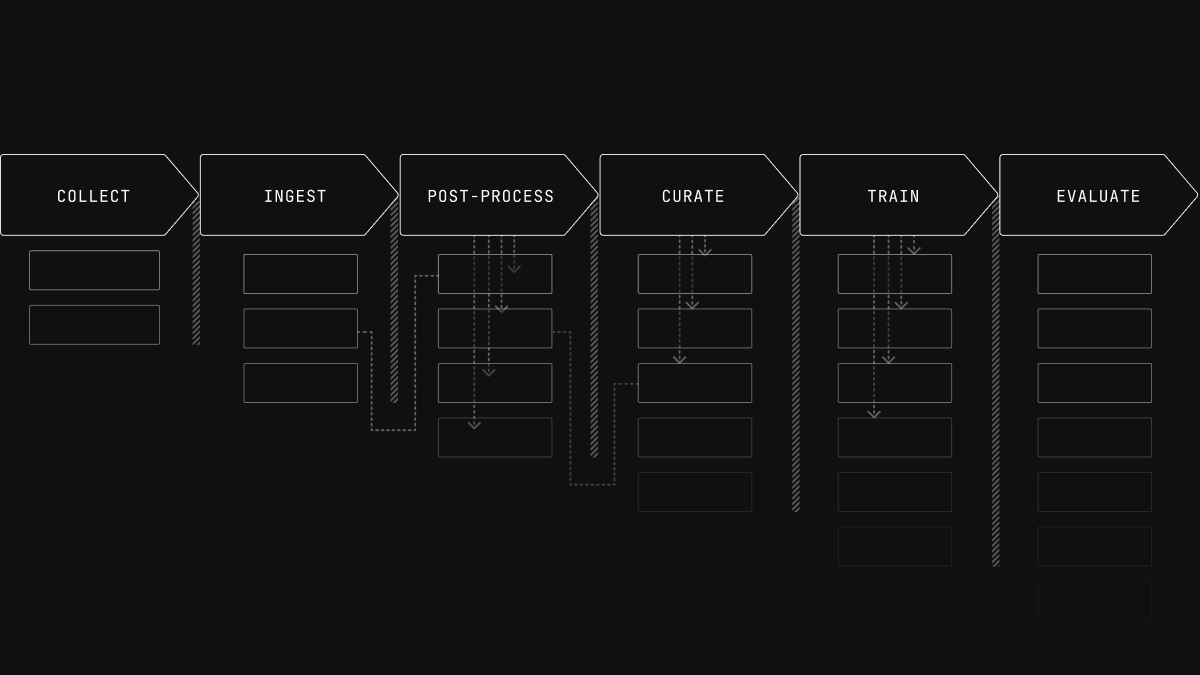
Rerun has been best known for visualizing multimodal time-series data. For the last year and a half, we've been quietly building the other pieces of a unified data layer to support the full journey from collection to training. With the 0.32 Rerun SDK release, those capabilities are coming to open source!
This is the biggest release since Rerun was originally open sourced three years ago, and represents a huge expansion of the kinds of work you can do with Rerun.
We're stabilizing the file format and adding a new set of lower-level read-and-write APIs for the files. We're adding a new API for manipulating Rerun data chunks designed for wrangling and normalizing real robotics data. We're expanding our MCAP and ROS 2 message support to make the out-of-the-box experience better. We're adding a new dataset review UI to make reviewing training datasets much faster. The open source catalog server now indexes into .rrd files on disk so you or your agent can write generic queries over directories of robotics recordings. Built on that same foundation we're also releasing a Pytorch dataloader so you can train robot models directly on .rrd files without needing to export to a training-specific format.
The robotics ecosystem has lacked a unified framework flexible enough to support the full lifecycle of robot learning data. With 0.32, that foundation is now emerging.
In addition to this huge open source release, we're also announcing Rerun Hub, our commercial data catalog and storage engine. Rerun Hub is now in private preview and extends the Rerun SDK to datasets backed by object storage. It provides a shared catalog and access layer for transforming, querying, visualizing, and streaming robot data at much larger scale while preserving the same data model and APIs.
Use Rerun Hub if your ambition is to scale data beyond what fits on your local machine - while moving fast! If you are a team building a product around robot learning and are thinking about your data layer, reach out.
The rest of this post has two parts. First, a primer on the data architecture we believe Physical AI needs in order to scale. Second, a tour through the new capabilities in Rerun SDK 0.32 that put that architecture into practice.
Robot learning needs a data layer purpose-built for physical data
As outlined in The Data Layer Tax for Robot Learning, much of the friction slowing Physical AI progress comes from trying to force physical data through infrastructure designed for traditional software and analytics workloads. What's needed is a data layer built for multi-rate, multimodal data, that supports everything you need to iterate on robot intelligence, from collection to training and deployment.
Coding agents mean users need full control of the compute and application layer
To serve the whole workflow of collection, normalization, post-processing, curation, and training, teams need a variety of different tools and compute jobs. Those tools and jobs can e.g. encode the specific ways a team operates or the techniques they use to drive data quality at scale, which make them a key area of differentiation that teams need to own.
Coding agents are making it increasingly feasible for teams to design these tools and compute jobs exactly the way they want, as long as they have code-level control. Because of this, very few teams will accept not having that control. That's why the Rerun SDK is fully open source and designed as a framework that you can build with rather than a walled garden SaaS platform. Even the viewer is designed as a library so you'll never be stuck. Rerun has always been code first and we've been doubling down on making it even easier to use for agents. That even includes upcoming work on fully headless rendering and viewer navigation to help agents see physical data just like humans.
Most teams are already building custom one-off applications and processing scripts tailored to their own workflows. Without building on top of a solid foundation you end up with vertical pieces that are hard to reason about and don't compose well, which puts a cap on productivity gains.
The data layer must handle the hard parts of using large-scale physical data
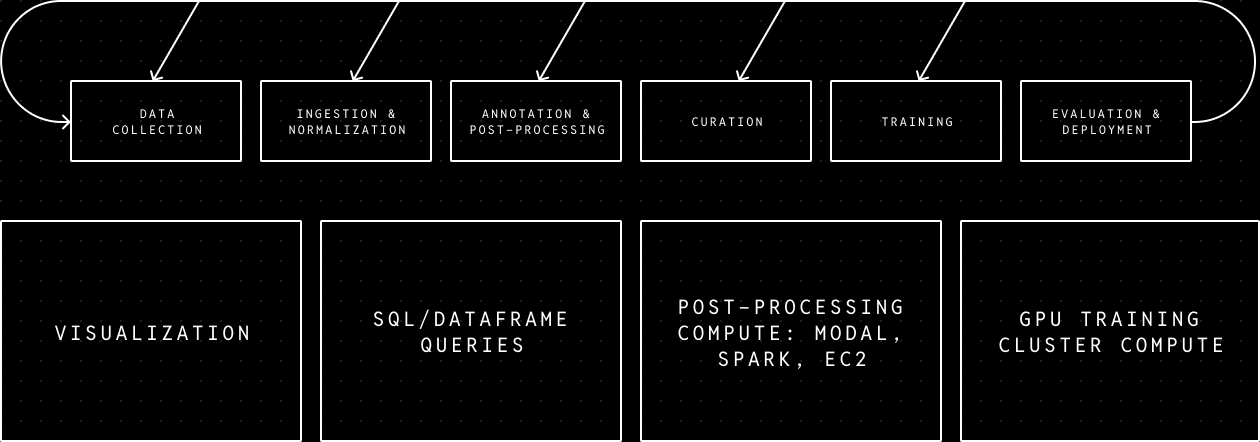
The core capabilities needed to serve the whole data journey from collection to model are visualization, analytical querying, transformation, and training. All of these capabilities need to deal with multi-rate, multimodal data that might carry robotics semantics like 3D relationships or shape. To avoid bugs and inconsistent data, you want to deal with the subtleties of this kind of data consistently wherever it's used. For example, time alignment and 3D transforms should behave consistently across preprocessing, querying, visualization, and dataset review.
To make it easy to iterate on both the data-experiment loop and the tools that power it, you want to build on top of a single unified data layer that makes handoffs trivial and the applications on top simple. That means the data layer needs to be flexible enough to handle the requirements from all the core application and compute capabilities. For example, visualization and compute both require fast random access of multimodal time series, while analytical queries require efficient column scans, and both large scale post-processing compute (CPU) and training (GPU) require high bandwidth parallel data streaming.
Physical data fundamentally behaves differently from web and business data, which means it benefits from different storage and query abstractions.
The core storage unit for physical data is a column chunk
Physical data has two differentiating characteristics:
The first is that it is multi-rate: different sensors will record data at wildly different frequencies. The GPS might be at 1-10Hz, the cameras at 10-30Hz, joint-angles at 100-200Hz, and IMU at 1kHz. In post-processing you might compute semantic embeddings for every 10th camera frame or scene descriptions at the start and end of each episode.
The second is that it is multimodal: different sensors record data of wildly different sizes. The IMU and GPS need only a handful of bytes to encode a couple numbers, while a RGB camera can use many MBs for each image frame.
If you were to store a robotics recording in a table where one row represents a time stamp, and a column represents a stream of data, the multi-rate aspect would generally make this table very sparse; for any given row most columns are likely empty. The multimodal aspect of the data leads to a large memory imbalance since a single row may contain cells that differ in size by orders of magnitude. Existing tabular data infrastructure handles this combination very poorly.
Multi-rate and multimodal data should be stored in chunks that each hold subsets of the rows and columns of a dataset. The ability to, for instance, place a million IMU samples in one chunk and only a few video packets in another chunk allows you to solve for both the sparsity and memory imbalance issues.

Within the chunk, column-oriented storage optimizes for better compression and column scan queries, while row-oriented storage optimizes for simple writes.
At Rerun we believe column chunks represent the best tradeoff for robot learning data systems, and we've standardized our architecture around them as the core storage abstraction.
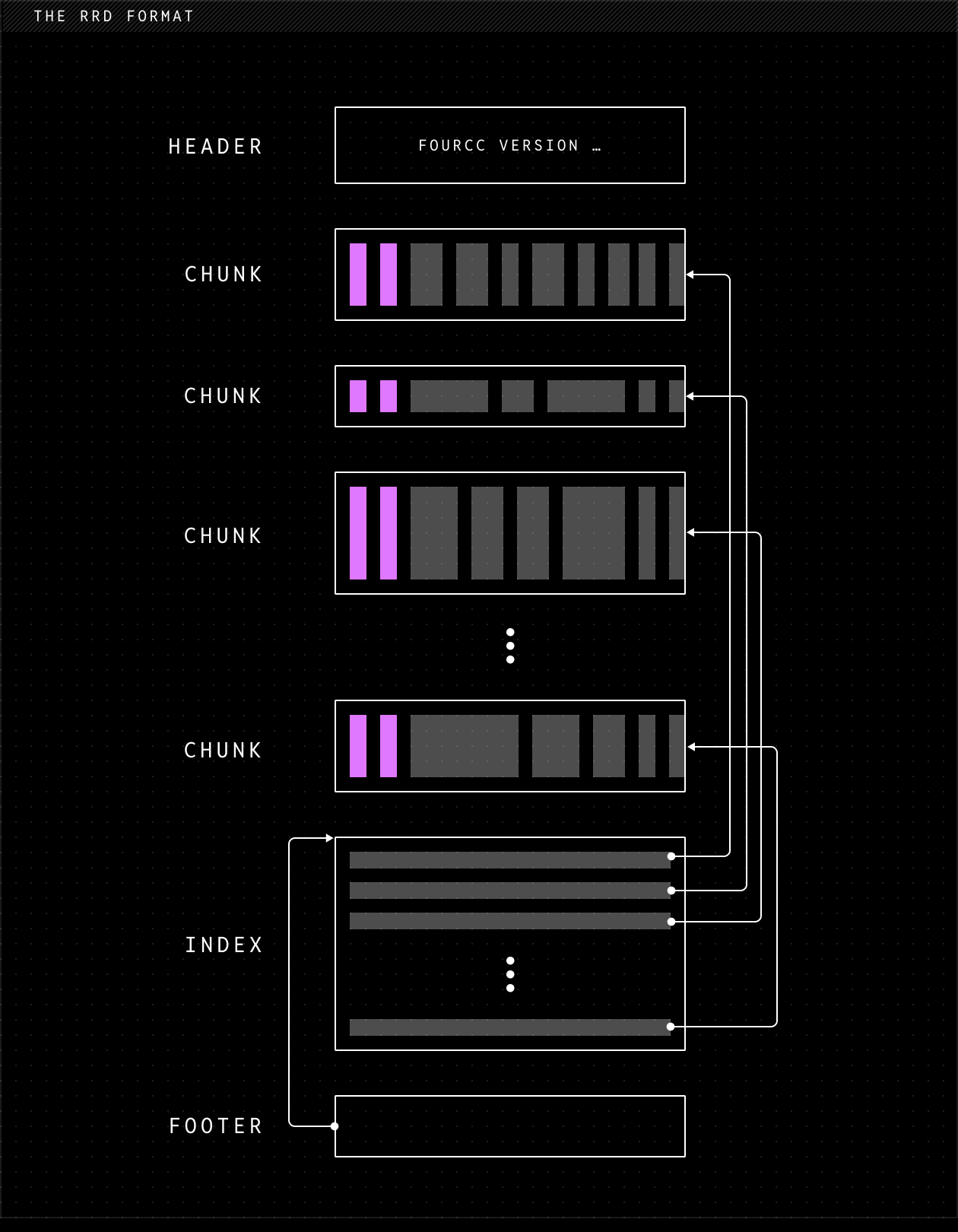
Rerun's .rrd file format is built around column chunks
Rerun's native file format, .rrd, is the on-disk representation of the column chunk abstraction. Internally, each column chunk is encoded as an Apache Arrow record batch together with semantic metadata describing how the data should be interpreted. Apache Arrow is the industry standard for data science, and using Arrow means we have a fast zero-copy path into DataFusion, Pandas, and Polars.
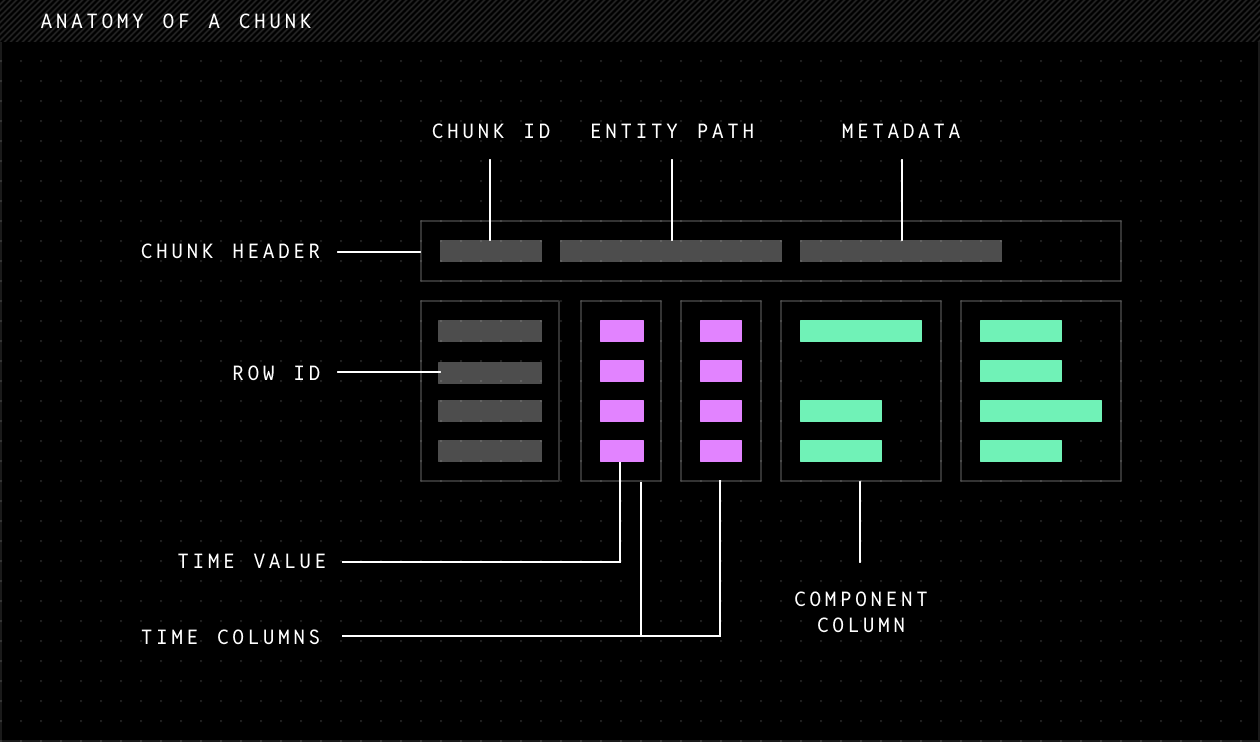
The metadata in each chunk contains semantic information about how to interpret the data ("this is an IMU sensor, this is a GPS, …") so that it can be carried through processing pipelines and still be automatically interpreted and visualized.
The encoded column chunks are wrapped in protobuf messages and concatenated to form an .rrd file. A footer at the end of the file points to an index, allowing fast random access to individual chunks without scanning the entire file.
Comparisons to other formats
Apache Parquet is a columnar on-disk format, commonly used together with Arrow. It organizes its data in row groups, but unlike chunks in .rrd, these groups cannot overlap: each row group contains all columns over a dense range of rows. This makes it unsuitable for multi-rate, multi-modal robotics data. You can append new rows, but you cannot append new columns (no schema evolution).
MCAP is a format for recording robotics logs on your robot. It is designed to be fast and flexible to write, with strong ROS compatibility. However, it is essentially a container format of opaque messages (encoded with JSON, protobuf, CBOR, etc) and not optimized for columnar analytical queries. Big scans and joins are also slow, since you need to decode each message.
Lance is a new format, explicitly built for multimodal data and random access (which is extremely important for training). Unlike Parquet, it supports schema evolution. However, a Lance dataset is still a vertical stack of row-aligned fragments, so multi-rate streams will bloat with nulls.
NCore is a new format from Nvidia, built for neural reconstruction. Multi-rate is supported natively via per-component timestamps, and spatial alignment via a pose graph. However, the schema is closed (canonical sensor components, not arbitrary user-defined data), it is Zarr-based rather than Arrow-native, and it is not built to serve a generic SQL / dataframe query engine.
Every feature your team needs that a file format doesn't provide means another pipeline to keep synchronized and additional tools to learn for your team to succeed. Rerun's format is the only option that can serve all the use cases needed to transform robot recordings into intelligence. It allows you to keep data at original timestamps, while still being able to query and view from the same datasource, and stream to training. It has enough structure to build unified data systems on top but is flexible enough to optimize for different read and write patterns.
An indexing, schema, and metadata layer on top of column chunks simplifies using physical data at scale
Scanning all chunks in a dataset to analyze a single signal scales poorly even for small datasets, so to use them effectively you need a metadata and indexing layer that can help finding the right chunks for any query. This looks a lot like the classic data lakehouse pattern. In our case, a single dataset or recording is made up of heterogeneous chunks that don't share the same schema. Classic data processing tools are built for dealing with tables that have a uniform schema. A lakehouse-style indexing and metadata layer for physical data therefore also needs to keep track of these individual schemas so it can materialize merged schemas of any stream on the fly so that classic data tools can work with it. For example, if you upgrade your IMU to one that publishes magnetic field data in its messages this addition is compatible with your older IMU that didn't contain this field, no need to re-write historical data for compatibility.
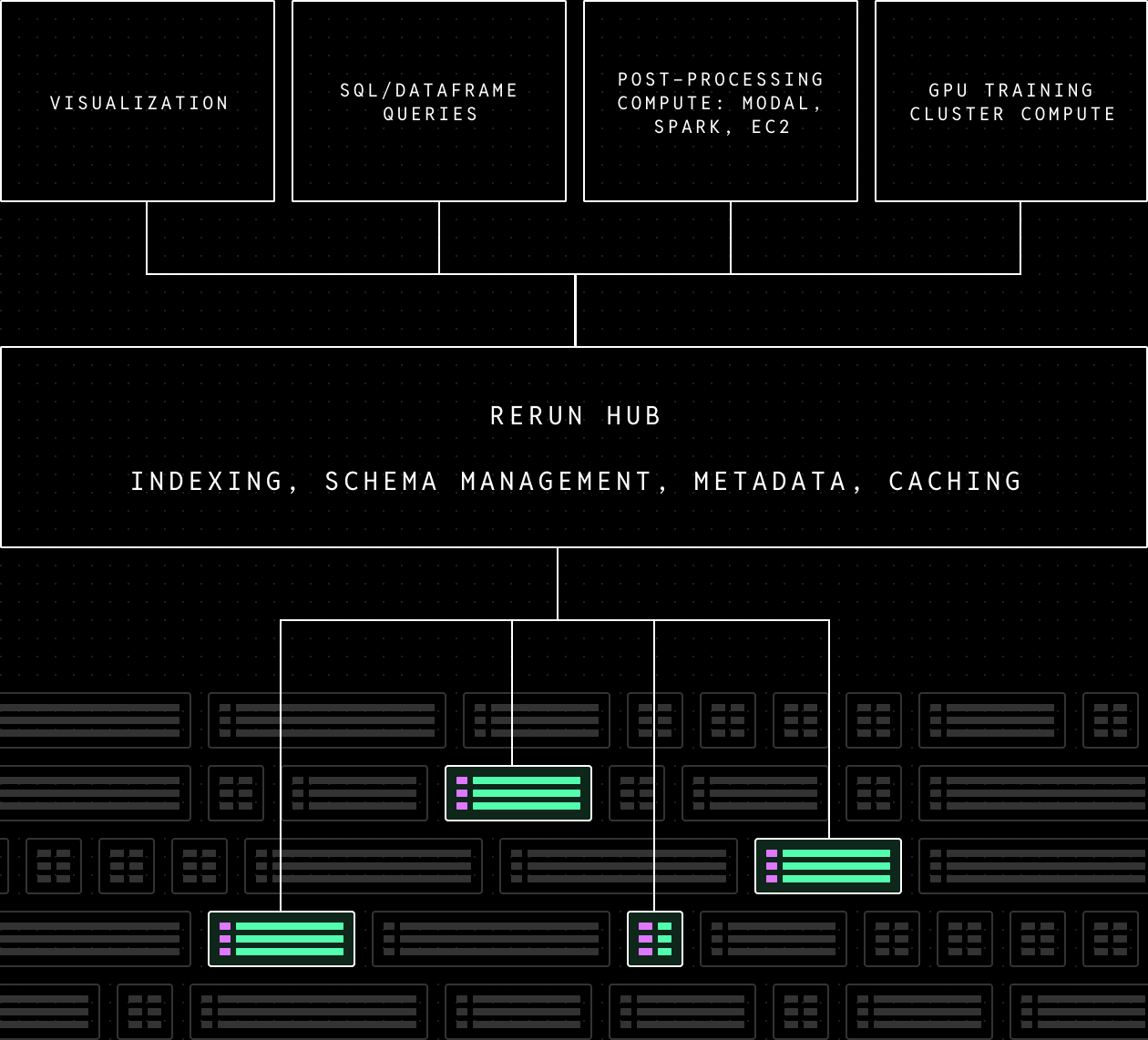
Column chunks paired with efficient indexing let you fetch exactly the data you need without paying a penalty for unrelated streams stored alongside it. You don't have to choose between making common operations fast and being able to chase long tail bugs because you exported common data to a separate warehouse.
In addition to performance benefits, this layer allows us to abstract away files and present a unified API for all the users of physical data in the layers above. Oftentimes robot data is stored in one file and calibration in another, abstracting these implementation details is an important part of reducing data friction and simplifying the compute and application layer.
Large scale processing and training requires selective streaming directly from object storage
Robot learning datasets can already get very large and will get much larger as teams follow scaling laws to achieve more and more capable models. To process this scale of data you often need to fan out to large numbers of CPUs for post-processing or GPUs for training. In these cases it's important that data throughput can scale with the needs of this compute.
Both for maximizing performance and minimizing egress costs, you want to run the compute close to the data. At the same time GPU compute can be hard to come by so many teams end up renting in different locations over time. All of these factors mean you want to be able to separate storage from the services that handle indexing and metadata.
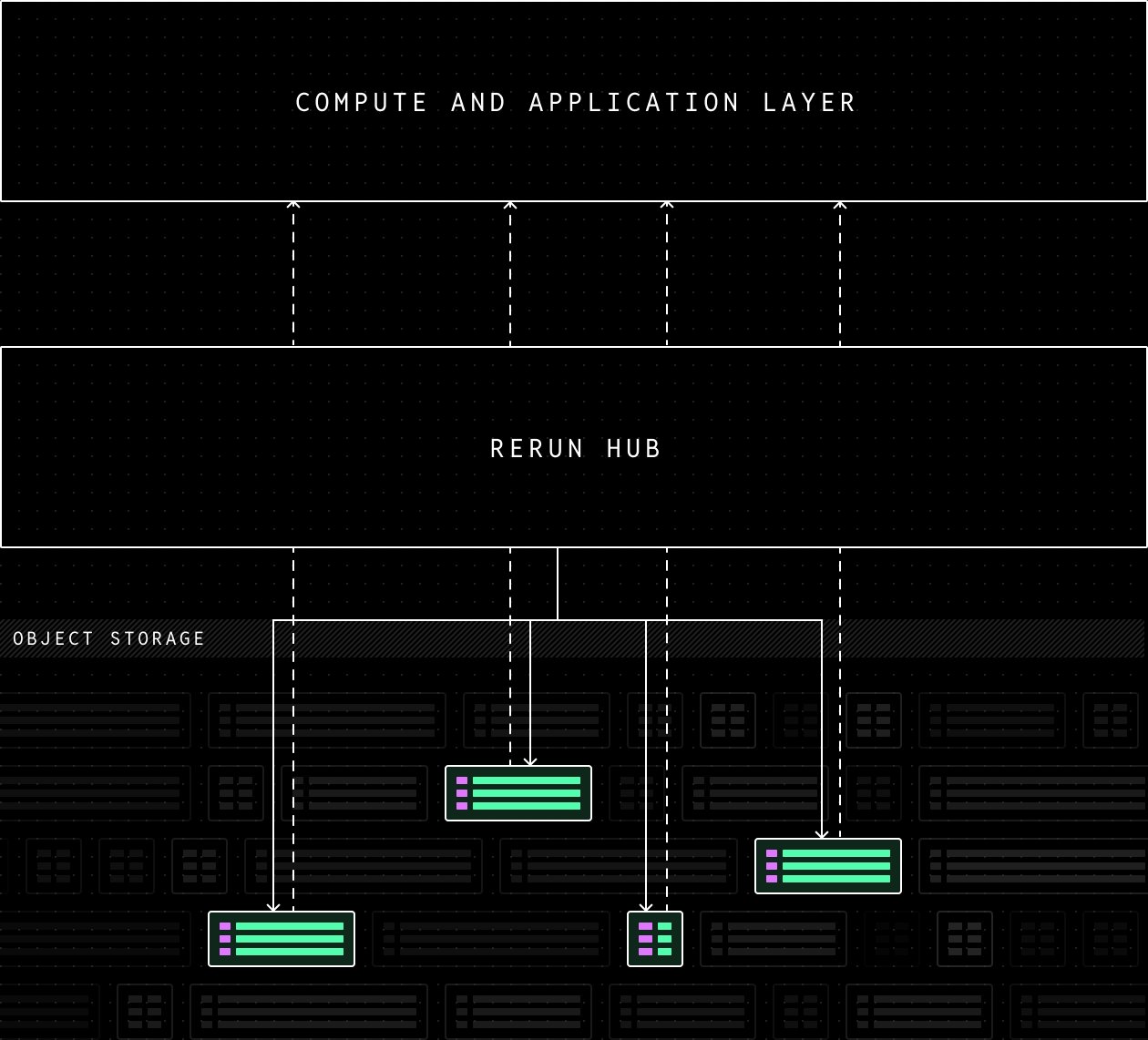
In Rerun, queries start from the Rerun SDK that then queries Rerun Hub, which is responsible for knowing which chunks are needed to resolve the query. Depending on the setting, the SDK either asks for chunks through a cached proxy in the Rerun Hub, or for byte ranges on object storage. This allows for a simplified access API, selective chunk streaming, and the maximum streaming bandwidth from the underlying object storage.
Rerun SDK 0.32 is a unified data toolkit for robot learning
Rerun 0.32 is the biggest release since it was originally open sourced in February 2023. It expands the practical use cases of the SDK from logging, visualizing and simpler querying to the full data journey from collection to training. What follows is a tour of the new features that highlight this expansion. Check out the release notes for more details.
A stable file format with chunk-level Python APIs
In Rerun 0.23 we announced version-to-version backwards compatibility for Rerun's .rrd file format. In practice we haven't broken compatibility between any versions since then and now feel confident to promise general backward compatibility on the file format. We will continue to evolve the format to push capabilities and performance, but old data will always load.
Prior to 0.32, you could only write .rrd files by using an importer from another format or the higher level log or send_columns APIs, and the only way to read data was through dataframe or SQL queries. With this release we're now introducing chunk-level read and write APIs, which give you precise control over the exact shape of your data.
Taken together these two changes mean .rrd is mature enough for a wide set of teams to build their data layers on.
Chunk processing APIs for robotics-native data wrangling
Robotics data is often messy. Normalizing data from multiple sources into something teams can analyze and train on gets complex fast. This part of the data pipeline often consists of cobbled together Python scripts that are slow and full of subtle bugs.
To solve these problems we're introducing a new set of (experimental) chunk processing APIs. They provide a uniform loader interface to formats like .rrd, MCAP, Parquet, and URDF that produce streams of Apache Arrow chunks. You can then easily define processing pipelines on top of those streams.
# Generate one stream per source to merge together
## Mcap with bulk of recorded data
mcap_stream = McapReader("my_file.mcap").stream()
## URDF with static assets
scene_urdf = UrdfTree.from_file_path("scene.urdf", static_transform_entity_path="/tf_static/scene")
## Static offset between two robotic arms that wasn't initially captured
with json_path.open() as f:
transform = json.load(f)["transform"]
offset_chunk = Chunk.from_columns(
"/tf_static/robot_offsets",
columns=rr.Transform3D.columns(**transform)
)
robot_offsets_stream = LazyChunkStream.from_iter([offset_chunk]).stream()
merged_stream = LazyChunkStream.merge(
mcap_stream,
scene_urdf,
offset_chunk,
)
merged_stream.write_rrd()Robotics data often comes in the form of deeply nested structs and data normalization and wrangling often means reshaping, casting and transforming their content. To meet that need we're also releasing Lenses, a declarative language for selecting and transforming this kind of data, inspired by jq.
## Manipulate a standard IMU message
### Extract the x component and cast to float 32
mcap_stream = mcap_stream.lenses(
MutateLens(
"Imu:accel",
Selector(".x").pipe(lambda arr: pc.cast(arr, pa.float32())),
),
content=["/imu"]
)These APIs have been explicitly designed for and tested with coding agents in mind, and we find that they have a much easier time producing correct and efficient code with the Rerun chunk processing APIs than with generic Python. In the future these chunk processing transforms will be able to run in the viewer and in the cloud via Rerun Hub in addition to the current SDK side executor.
Expanded built-in support for MCAP, ROS 2 types, and robotics visualizations
We think it's critical that it's easy to ingest and make all robotics data useful in Rerun. At the same time there is a lot of data that can be perfectly handled without customization, and we continue to improve that experience on every release. 0.32 brings improved performance and more out of the box support for MCAP and common ROS 2 types as well as an expansion of available visualizations. See the updated list of messages with built-in support here.
Occupancy grids, or 2D maps in 3D are important for mobile robots and have been a heavily requested feature in Rerun for a while. 0.32 therefore adds the new GridMap archetype and visualizer, paired with built-in support for the corresponding ROS 2 messages.
Another common request has been the ability to visualize state changes over time. 0.32 brings a new experimental State Timeline View. If you've been waiting for this view in Rerun we'd love your feedback on what more you'd like to see from the view.
Catalog server with indexed SQL or dataframe queries over the contents of many recordings on disk
The Catalog APIs in Rerun SDK allow you to write fully generic SQL or Dataframe queries on robotics datasets. When connected to Rerun Hub, this has supported large scale datasets for some time, while the open source server has only supported datasets that fully fit in memory. With 0.32 we're expanding the open source catalog server to index into byte ranges of files on local disk so you can now easily analyze any local directory of robot recordings in .rrd files with only the open source SDK.
with rr.server.Server(datasets={"sample_dataset": directory_of_rrds}) as srv:
client = srv.client()
df = client.get_dataset("sample_dataset").reader(index="real_time")
# Count the number of observations where the first gripper joint is greater than some threshold
df.filter(col("/action/gripper_position:Scalars:scalars")[0] > 0.5).count()A new UI for rapid review of datasets for training and evaluation
In 0.32 we're shipping the first version of our (experimental) dataset review tool. It lets you quickly eye-ball many recordings at once, to go anomaly hunting and build intuition for your data. It also lets you flag recordings, making it useful as a simple annotation tool. The view is configured using a normal Rerun blueprint.
Many robot learning teams have asked for this functionality and we'd love all of your feedback on how to turn this into the most efficient dataset review tool possible.
A dataloader for robot learning that supports simple dataset mixing and random seeks into .rrd files
We've started work on one of our most requested features: a PyTorch dataloader for Rerun! The new rerun.experimental.dataloader module exposes Rerun recordings as iterable or map-style PyTorch datasets, streaming encoded images, scalars, and compressed video (h264/h265/av1) on the fly. Random access, multi-worker prefetching, and DDP support work out of the box. It is compatible with both the OSS catalog server and our commercial product Rerun Hub for when you want to train directly on large datasets backed by object storage.
source = DataSource(
dataset=client.get_dataset("my_robot_data"),
segments=[
"ILIAD_50aee79f_2023_07_12_20h_55m_08s",
"ILIAD_5e938e3b_2023_07_20_10h_40m_10s",
],
)
fields = {
"state": Field("/observation/joint_positions:Scalars:scalars", decode=NumericDecoder()),
"action": Field("/action/joint_positions:Scalars:scalars", decode=NumericDecoder()),
"Image.wrist": Field(
"/camera/wrist:VideoStream:sample",
decode=VideoFrameDecoder(codec="h264", keyframe_interval=500, fps_estimate=15.0),
),
}
ds = RerunIterableDataset(
source=source,
index="real_time",
fields=fields,
timeline_sampling=FixedRateSampling(rate_hz=15.0),
)
loader = DataLoader(ds, shuffle=False)We're incredibly excited to release this training dataloader for the community to start experimenting with. We intend to make this the best streaming dataloader for robot learning imaginable and would love all your feedback and requests.
Being able to train directly off of the same data layer you use for visualization, analysis, and transformation is crucial for teams to be able to truly unify their data layers, which is how they can really simplify systems and accelerate experiment cycles.
Rerun Hub is in private preview and built for scale
Over the last year and a half we've been quietly building out the data layer needed to accelerate bringing robot learning to valuable real world applications together with an early set of great startups and labs. We're currently handling petabytes of robot training data and are at a point where we're ready to onboard more teams to our commercial product Rerun Hub, which is now entering into private preview.
Rerun Hub is a catalog and storage engine that connects to the open source Rerun SDK to make it easy to work with robot learning data from collection to training and deployment. It acts as a uniform management and access layer that powers all the core data capabilities from ingestion, visualization, analytical queries, transformation, and training. Data can be stored in any S3 compatible object storage, and Rerun Hub efficiently mediates direct selective-streaming from object storage to the Rerun SDK in your training or massively parallel post-processing jobs. The centralized hub also simplifies collaboration and automated review by making it easy to construct sharable data links either through code or interactively in the viewer.
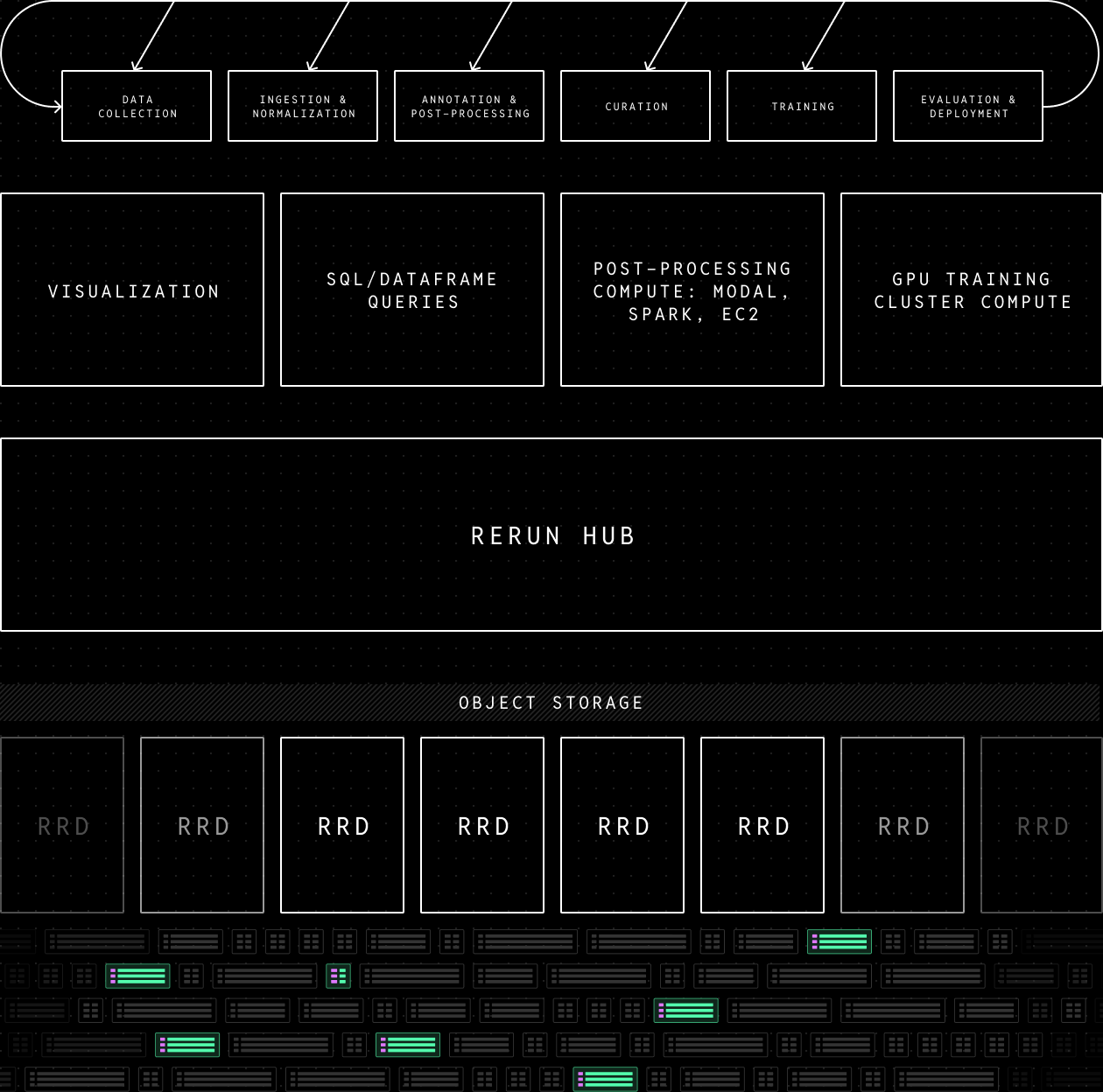
If you're building intelligent robots and are interested in upgrading your data layer so you can iterate faster, reach out. For teams that have already hit some scale with complex existing systems, Rerun is easy to adopt piecemeal and we can also offer forward deployed engineers to help you upgrade without moving core people off other top priorities.