Spatial computing and XR
Decoupling human and camera motion from videos in the wild
This example is a visual walkthrough of the paper “Decoupling Human and Camera Motion from Videos in the Wild”. All the visualizations were created by editing the original source code to log data with the Rerun SDK.
Visual paper walkthrough
SLAHMR robustly tracks the motion of multiple moving people filmed with a moving camera and works well on “in-the-wild” videos. It’s a great showcase of how to build working computer vision systems by intelligently combining several single purpose models.
“Decoupling Human and Camera Motion from Videos in the Wild” (SLAHMR) combines the outputs of ViTPose, PHALP, DROID-SLAM, HuMoR, and SMPL over three optimization stages. It’s interesting to see how it becomes more and more consistent with each step.
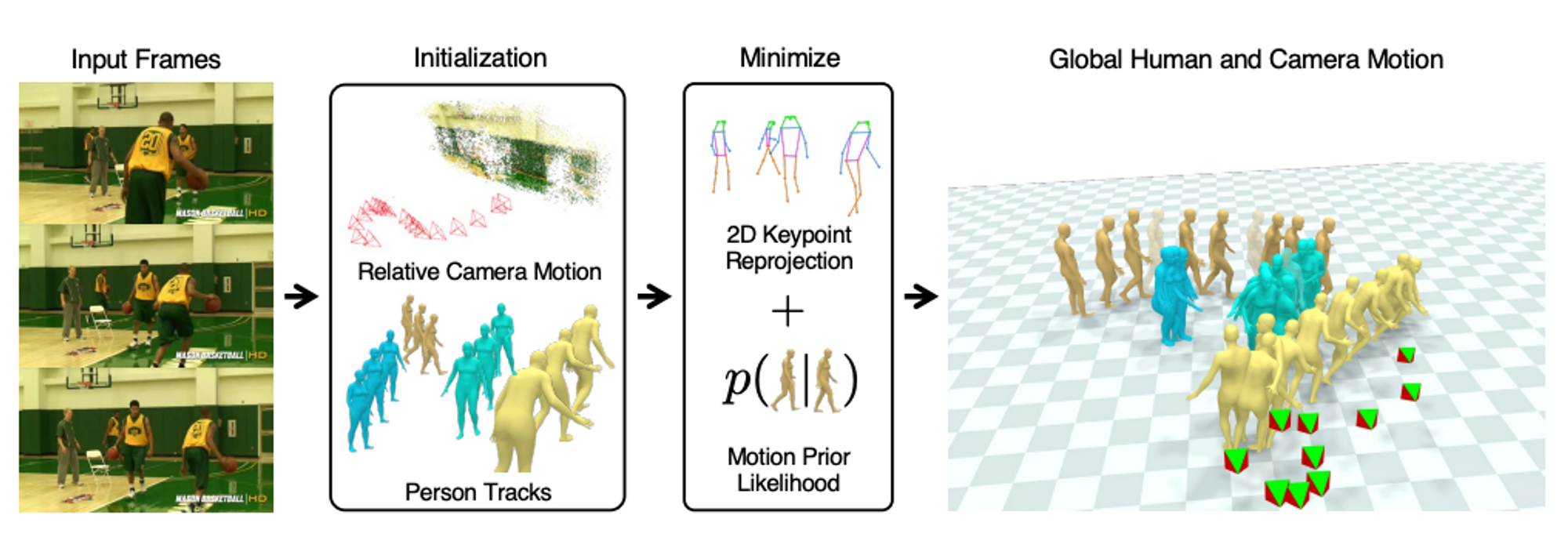
Input to the method is a video sequence. ViTPose is used to detect 2D skeletons, PHALP for 3D shape and pose estimation of the humans, and DROID-SLAM to estimate the camera trajectory. Note that the 3D poses are initially quite noisy and inconsistent.
In the first stage, the 3D translation and rotation predicted by PHALP is optimized to better match the 2D keypoints from ViTPose. (left = before, right = after)
In the second stage, in addition to 3D translation and rotation, the scale of the world, and the shape and pose of the bodies is optimized. To do so, in addition to the previous optimization term, a prior on joint smoothness, body shape, and body pose are added. (left = before, right = after)
This step is crucial in that it finds the correct scale such that the humans don't drift in the 3D world. This can best be seen by overlaying the two estimates (the highlighted data is before optimization).
Finally, in the third stage, a motion prior (HuMoR) is added to the optimization, and the ground plane is estimated to enforce realistic ground contact. This step further removes some jerky and unrealistic motions. Compare the highlighted blue figure. (left = before, right = after)
For more details check out the paper by Vickie Ye, Georgios Pavlakos, Jitendra Malik, and Angjoo Kanazawa.