Spatial computing and XR
SimpleRecon: 3D reconstruction without 3D convolutions
This example is a visual walkthrough of the paper "SimpleRecon: 3D reconstruction without 3D convolutions". All the visualizations were created by editing the original source code to log data with the Rerun SDK.
Visual paper walkthrough
SimpleRecon is a back-to-basics approach for 3D scene reconstruction from posed monocular images by Niantic Labs. It offers state-of-the-art depth accuracy and competitive 3D scene reconstruction which makes it perfect for resource-constrained environments.
SimpleRecon's key contributions include using a 2D CNN with a cost volume, incorporating metadata via MLP, and avoiding computational costs of 3D convolutions. The different frustums in the visualization show each source frame used to compute the cost volume. These source frames have their features extracted and back-projected into the current frames depth plane hypothesis.
SimpleRecon only uses camera poses, depths, and surface normals (generated from depth) for supervision allowing for out-of-distribution inference e.g. from an ARKit compatible iPhone.
The method works well for applications such as robotic navigation, autonomous driving, and AR. It takes input images, their intrinsics, and relative camera poses to predict dense depth maps, combining monocular depth estimation and MVS via plane sweep.
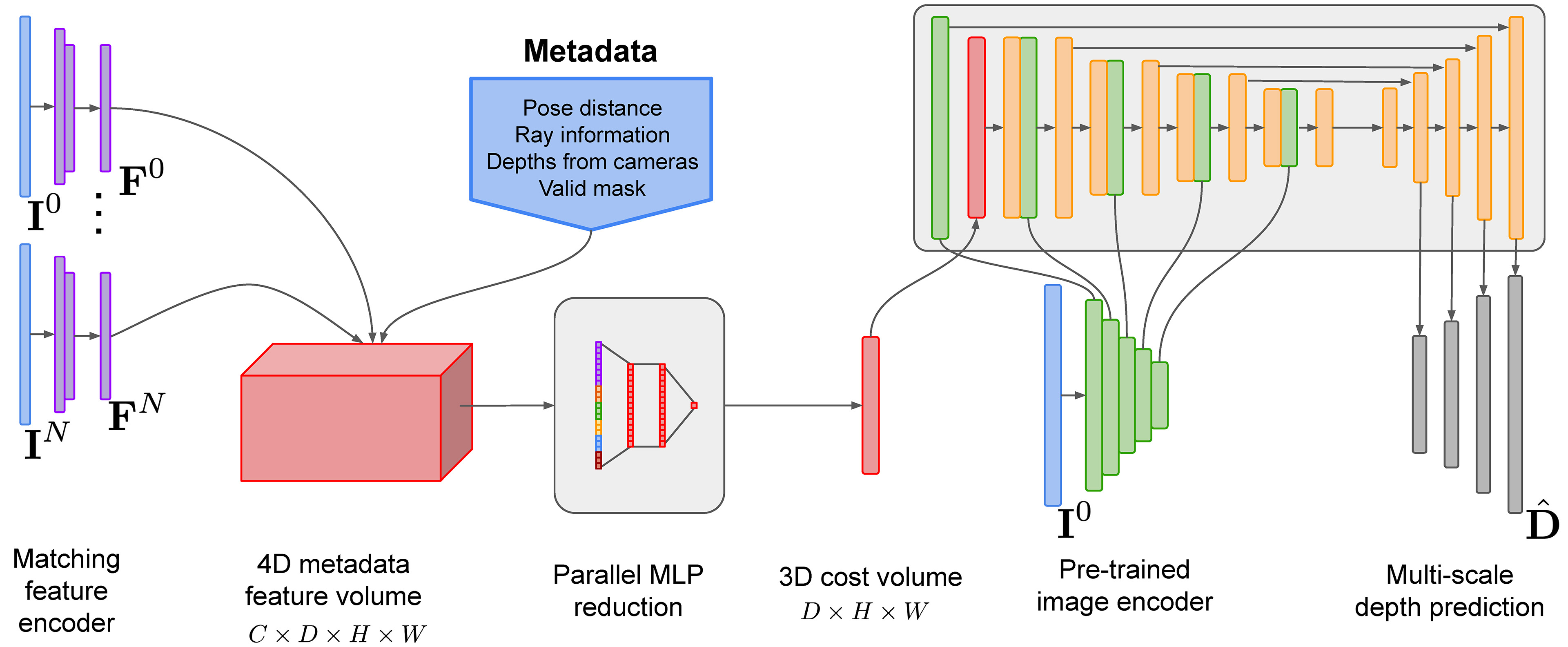
Metadata incorporated in the cost volume improves depth estimation accuracy and 3D reconstruction quality. The lightweight and interpretable 2D CNN architecture benefits from added metadata for each frame, leading to better performance.
If you want to learn more about the method, check out the paper by Mohamed Sayed, John Gibson, Jamie Watson, Victor Prisacariu, Michael Firman, and Clément Godard.