From the Evolution of Rosbag to the Future of AI Tooling
Thirteen years ago, Willow Garage released ROS (the Robot Operating System) and established one of the standard productivity tools for the entire robotics industry. Back then, as a member of the ROS core team, I worked on the rosbag storage format and many of the tools it powered. This remains one of the most rewarding and impactful pieces of software I have developed. Rosbag, and other formats like it, are still widely used across the robotics industry, serving a crucial role in enabling developers to understand and evaluate their systems.
Today, the most significant ongoing change in robotics is the use of modern AI in production systems. Creating, training, and integrating the models that power these systems places new demands on development workflows and tooling. Still, the core motivations that drove the early evolution of the rosbag format are as present as ever and influence how we at Rerun think about the next generation of productivity tools for real-world AI. To set the stage for some of that future work, I’d like to share the original story of how the rosbag format evolved.
 A bag of ROS turtles (credit: Midjourney)
A bag of ROS turtles (credit: Midjourney)
Where It All Started
In 2008, I had the great privilege of joining Willow Garage. Willow Garage was a privately financed robotics research lab with the unique vision of accelerating the entire robotics industry. The fundamental problem Willow Garage wanted to solve was that robotics research and development lacked a functional robotics “stack” to build on top of. Not only did this slow down progress since developers were constantly spending time reinventing the wheel, it dramatically hindered collaboration because developers, left to their own devices, rarely build compatible wheels. Before Willow Garage, I had worked on early autonomous vehicles as part of the DARPA Grand Challenge and aerial sensing systems at Northrop Grumman. I was all too familiar with the pain of building complex systems on top of an ad-hoc home-grown foundation of mismatched tools and libraries.
Willow Garage wanted to solve this problem by building a flexible open-source robotics framework (ROS) and, in parallel, manufacturing a capable robot tailored to the needs of robotics researchers (the PR2). The idea was to build and give away identical robots to ten universities alongside several that would be used in-house by a team of researchers at Willow Garage. By co-developing ROS alongside a shared hardware platform, we could bootstrap an environment where we could get fast feedback not just on the core functionality but things that would push the envelope of collaboration and shared development.
 The first collection of PR2s distributed to the Beta Program (credit: Willow Garage)
The first collection of PR2s distributed to the Beta Program (credit: Willow Garage)
(If you want even more ROS and Willow Garage history, check out this IEEE spectrum article.)
Running Code Without Robots
One problem common to robotics is that physical systems severely limit the ease of development. Developers are rarely able to run their code on a live robotic system as quickly and frequently as they might otherwise like to.
If you lack access to a robot or need to share one with others in a lab, you may initially think the robot itself is the bottleneck. However, even at Willow Garage, where we were building a sizable fleet, running code directly on the robot was still quite time-consuming. The need for the robot to interact physically with the world makes it far slower than the average edit-compile-run loop of a software engineer. Moreover, the physical world adds significant non-determinism to the system, making it challenging to recreate a specific scenario where something unexpected might have happened.
One way of addressing this is to stop using real robots altogether and switch to faster-than-realtime simulators. Simulators were also a big part of the solution space within ROS and continue to be an area of investment across the robotics industry today. However, the fidelity of simulators is often limited compared to running in a real system, and high-fidelity simulators eventually start to run up against similar resource constraints.
The other way of addressing this is to derive as much value as possible from whatever time is available to run code live on the robot. The initial goal of rosbag was to create this added value by enabling developers to easily record data about the live robot session, move that data somewhere else, and then later seamlessly playback that recorded data to make use of it in different ways.
Basic Record and Playback
On the recording side, the core architecture of ROS greatly simplified the design of rosbag. ROS encourages users to follow a distributed microservices architecture. Systems are split into separable compute elements, called "nodes," which communicate over shared busses called "topics." Any node can publish a message to a topic, and other nodes interested in those messages can receive them.
 A ROS network and the rosbag recorder
A ROS network and the rosbag recorder
This architecture makes it straightforward to produce a recording of everything meaningful happening in the system by listening passively in on all of the available topics. As part of the IPC layer, the publishing nodes are responsible for serializing the messages into discrete binary payloads. Rosbag can then receive these payloads, associate them with meta information such as timestamp, topic-name, and message-type, and then write them out to disk. This data was all the early versions of rosbag needed to contain: a repeating series of timestamped message payloads in a single file. We called this a ".bag" file.
 Overview of the rosbag V1.1 format
Overview of the rosbag V1.1 format
In contrast to recording, the playback function does this in reverse. Rosbag sequentially iterates through the saved messages in the bag file, advertises the corresponding topics, waits for the right time, and then publishes the message payload. Because rosbag directly uses the serialized format to store and transmit messages, it can do this without knowing anything about the contents. But for any subscribers in the system, the messages look indistinguishable from those produced by a live system.
This model established a powerful pattern for working with the robots:
- Any time a developer ran code on the robot, they would use rosbag to capture a recording of all the topics. Rosbag could write all of the data directly to robot-local storage. At the end of the session, the recording could be transferred off the robot to the developer's workstation, put in longer-term storage, or even shared with others.
- Developers could later inspect the data using the same visualization and debug tools as the live system but in a much more user-friendly context. One of the most powerful aspects of this offline playback is that it enabled additional functionality such as repeating, slowing down, pausing, or stepping through time, much as one might control the flow of program execution in a debugger.
- This offline playback could further be combined with new and modified code to debug and test changes. Playing back a subset of the bag file, such as the raw sensor data, into new implementations of algorithms and processing models enabled developers to compare the new output with the initial results. Direct control of the input and the ability to run in a workstation-local context made this a superior development experience to running code on a live robot.
Developers could sometimes go for multiple days and hundreds of iterations of code changes while working with the data from a single recording.
Enhancements to a Bag-centric Workflow
As developers started doing a more significant fraction of their development using bags instead of robots, we started running into recurring problems that motivated the next set of features.
Because ROS1 encoded messages using its own serialization format (conceptually similar to google protobuf), it meant doing something with a bag file required your code to have access to a matching message schema. While we had checks to detect the incompatibility, playing back a file into a system with missing or incompatible message definitions would generate errors and otherwise be unusable. To solve this, we started encoding the full text of the message definition itself into the bag during recording. This approach meant generic tools (especially those written in python, which supports runtime-loading of message definitions) could still interpret the entire contents of any bag, regardless of its origin. One tool this enabled was a migration system to keep older bags up-to-date. When changing a message definition, a developer could register a migration rule to convert between different schema iterations.
Additionally, recording every message in the system meant bags could end up containing millions of messages spread over tens or hundreds of gigabytes. But often, a developer was only interested in a small portion of the data within this file when testing their code. Very early versions of the rosbag player allowed a user to specify a start time and duration for playback. Still, even if rosbag skipped the steps related to reading and publishing, the format required sequentially scanning through every message in the file to find where to start. To address this, we began including a time-based index of all the messages at the end of the file. Not only did this allow the reader to jump directly to the correct place to start playing, but it also made it much easier to only play back a subset of the topics.
 Overview of the rosbag V1.2 format
Overview of the rosbag V1.2 format
During recording, rosbag still wrote records incrementally to the file, just as before. However, when closing the file, rosbag would append a consolidated copy of the message definitions and indexes at the very end. Since the index is just a performance optimization for data already written to the file, the rosbag tool could regenerate it by scanning the file sequentially from the beginning. This structure meant files could still be recovered and re-indexed if a crash occurred mid-recording -- a vital property for recordings that might take several hours to produce.
More Than Just Playback
Making rosbags easier to migrate and faster to work with ultimately meant developers found themselves with more bags. The need to filter, split, crop, merge, curate, and share bags became increasingly commonplace. Additionally, users often wanted a high-level overview of a bag to figure out where to seek during playback. While the existing playback tool could support these operations crudely, we eventually needed a new approach to working with bags more directly.
We developed another revision of the rosbag format to solve this problem and created new libraries to support a more direct access model. Most notably, this version of the format introduced an internal partitioning called a "Chunk." Chunks are blocks of messages, usually grouped by time or message-type and optionally compressed. Each chunk importantly includes a sub-index describing the messages it contains. Rather than a single index, the end of the bag now had a collection of Chunk Info records with each chunk's location and higher-level information about its contents.
 Overview of the rosbag V2.0 format (not to be confused with the ROS2 bag format)
Overview of the rosbag V2.0 format (not to be confused with the ROS2 bag format)
This format and the new libraries enabled us to build new GUI tools like rxbag that could directly open and view the bag's contents. These tools included functionality like per-topic overviews of messages over time, thumbnail previews generated by random access to strategic locations, inline plotting of values from specific topics, and fast scrubbing both forward and backward in time. At a minimum, the tool could use the included schema to create a preview of any message in the file with a textual json-like representation. After using these tools to find a location of interest, a developer could still publish the relevant portion of the stream using the traditional playback model.
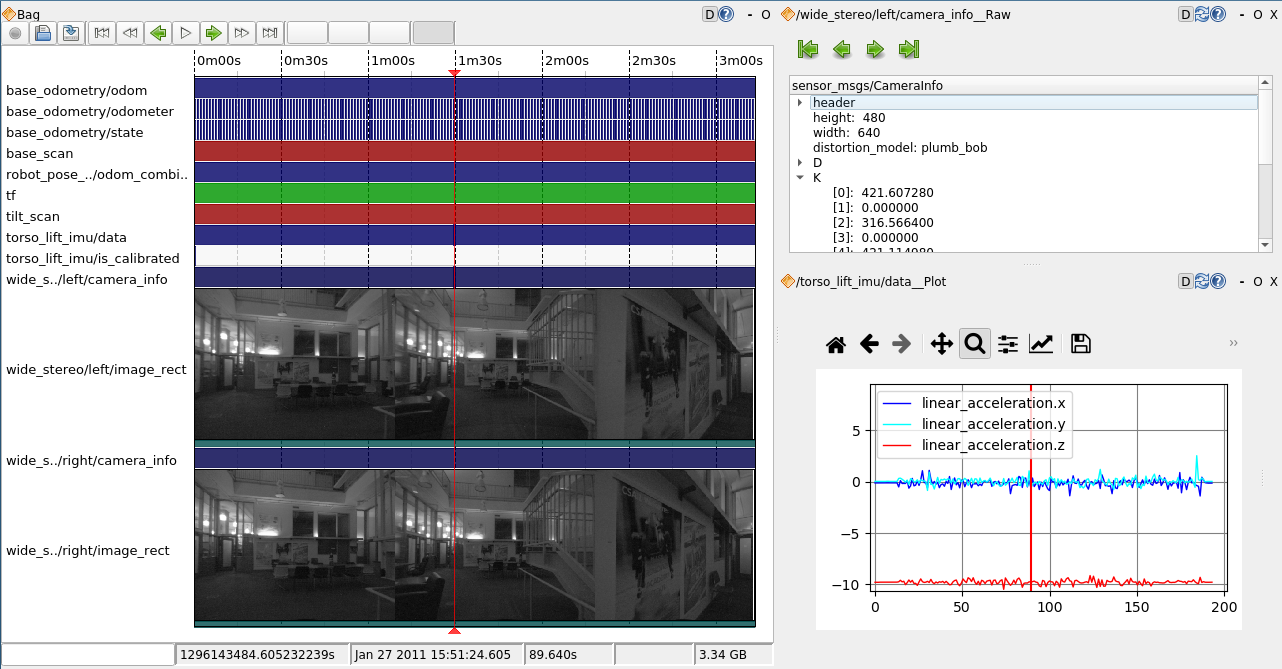 A Screenshot from the rqt_bag inspection tool.
A Screenshot from the rqt_bag inspection tool.
These lower-level access libraries also opened up new possibilities. For example, a developer could now write more "batch-style" offline processing jobs without the constraints of the runtime system. This style of job was more suited to higher-performance filtering or transformation tasks.
Good Enough for a Generation
And that was when rosbag generally crossed a critical usability threshold. It was good enough for what people needed to do with it. The rosbag format has remained relatively unchanged since mid-2010 as a foundational piece of the ROS ecosystem. Although replaced in ROS2 with alternative storage mechanisms, it is still the recording format for ROS1, which won't see end-of-life until 2025 -- a remarkable 15-year run of powering robotics data collection, inspection, and playback use-cases.
To summarize, there are a few things that made rosbag truly useful for the ROS community:
- It is nearly free to use (if you are using ROS). By taking advantage of existing messages in the system, rosbag requires no extra code to start making valuable recordings.
- Similarly, a powerful playback system also makes it easy to use the data in conjunction with existing algorithms while bringing additional functionality related to control of time and repeatability.
- Each bag exists as a singular self-contained file with no assumptions about the computer, path, or software context that produced it. You can freely move, save, and share it as an atomic unit. The included schema means the data can always be extracted, even working with files from older versions.
- The built-in index means rosbag tools function efficiently for common use cases, even when dealing with large files.
- Direct-manipulation libraries allow developers to process .bag files in alternative ways outside the core ROS execution paradigm.
- More than just a file format, an ecosystem of generic tooling brings convenient support for visualization, inspection, and file manipulation.
Beyond Rosbag
Perhaps the most controversial aspect of the original rosbag format was the intrinsic dependency on the ROS message definition format and the ROS framework. On the one hand, this choice meant all users of ROS could more easily work with any bag file, improving interoperability within the community. On the other hand, this precluded adoption from users unable to take on such significant dependency. An all too familiar story is startups and research labs, again, rolling their own rosbag-like format from scratch, precluding interoperability with standardized tools.
As part of a move to better interoperate with commercial use cases, ROS2 transitioned to a generic middleware architecture supporting alternative transport and message serialization backends. This transition also introduced a storage plugin system for rosbag instead of a single definitive format. The initial storage plugin for rosbag2 leveraged sqlite3. While the sqlite3 storage plugin takes advantage of a mature open-source library and brings more generalized support for indexing, querying, and manipulating files, it also misses out on some of the original rosbag features. A few downsides of this direction are that it gives up streaming append-oriented file-writing and lacks self-contained message schemas.
At this point, the most logical evolutionary descendent of rosbag is the open-source MCAP format, developed by foxglove as both a standalone container format and an alternative storage backend for rosbag2. MCAP directly adopts many of the original rosbag file format concepts while further adding support for extensible message serialization. It also cleans up a few of the rough edges, such as being more explicit about separate data and summary sections, avoiding the need to mutate the rosbag header, and moving to a binary record-metadata encoding.
 Overview of the MCAP format
Overview of the MCAP format
Further removed from ROS, other formats are similarly motivated by the need for a portable, stream-oriented, time-indexed file format. For example, the facebook research VRS (Vision Replay System) format was developed more specifically for AR and VR data-capture use cases but aims to solve many of the same problems. Rather than using existing serialization formats and generalizing the schema support, VRS uses its own data layout encoding. While this adds a lot of power to the VRS library regarding data versioning and performance, it also adds a fair bit of complexity. Similar to the ROS2 approach with sqlite3, VRS abstracts this complexity behind an optimized cross-platform library. However, this approach makes it challenging to work with a raw VRS file without using the provided library to process it.
What's Needed for the Future?
Great log-replay tools have become an essential part of building successful robotics and perception systems for the real world. Formats like MCAP and VRS give us a great foundation to build upon but are unlikely to be the end of this evolutionary arc.
There have been numerous developments in the years following the design of the rosbag format. An explosion of sensors and energy-efficient computing has unlocked new possibilities for hardware availability, while AI has gone from promising to breathtakingly powerful. The opportunities to solve real-world problems with these technologies have never been greater. At the same time, teams need to be more efficient with their resources and get to market faster.
So what features do the next generation of tools for real-world I need to incorporate?
Capture More than Runtime Messages
The current generations of log-replay tools build on top of schematized “message-oriented” systems like ROS. While this paradigm makes capturing data along the interface boundaries easy and efficient, it can introduce significant friction when capturing data from deeper within components or outside the system runtime. Future tools must give developers enhanced visibility across contexts ranging from core library internals to prototype evaluation scripts.
Easily Express Relationships Between Data Entities
When analytics and visualization tools know about the causal, geometric, and other relationships between data entities, they can provide developers with powerful introspection capabilities. Making it easy for developers to express these relationships effectively requires making them first-class citizens of the data model in a way that is difficult to achieve with current log-replay tools.
Support More General and Powerful Queries
The time-sequential index of events in a system only tells part of the story. To fully understand and explore the relevant data, developers need access to sophisticated and interactive querying and filtering operations. The next generation of tools should allow users to compare and aggregate across runs or any other dimension easily.
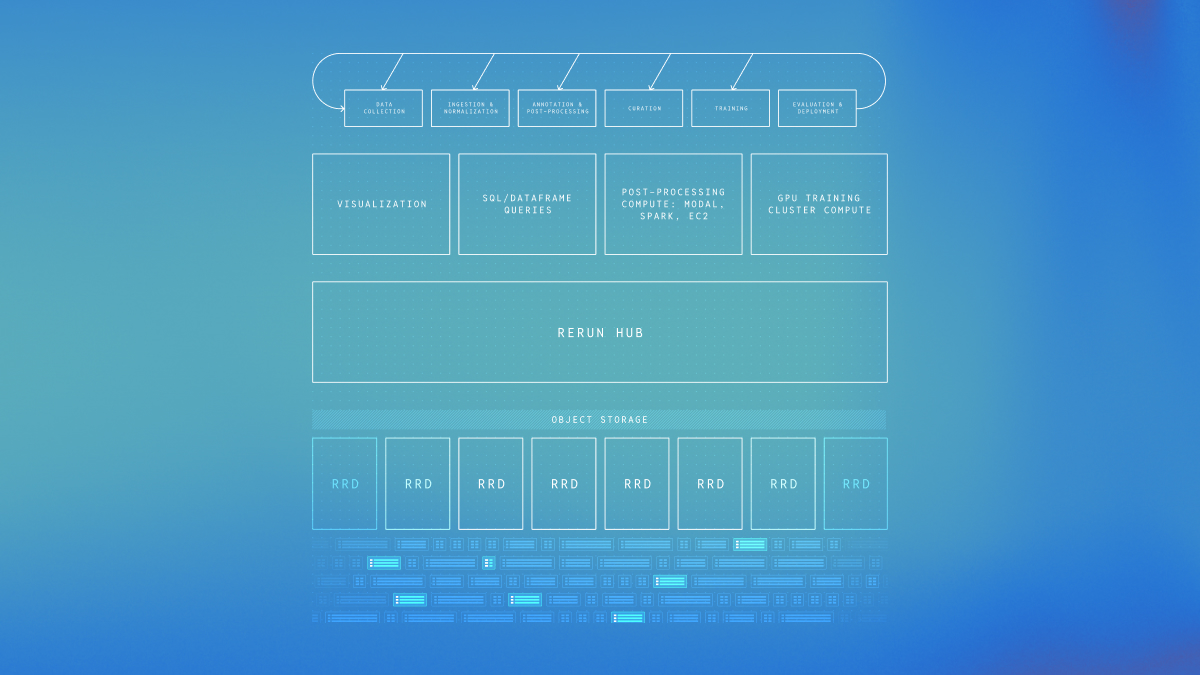
Robotics and AI/ML Workflows are Merging
Established practices from the robotics industry are mixing with workflows from the AI/ML community. This will continue and is necessary for achieving widespread success with AI in the real world. Both traditions will need to learn from the strengths of the other.
At Rerun, we’re building a new generation of tools informed by these old lessons and new demands. Much like in the early days of ROS, it’s clear there’s an opportunity to transform the workflows of a new generation of teams. As with the development of rosbag, the steps we take along the way will need to be iterative and incremental, driven by real feedback and use.
In order to work as closely as possible with the community, we plan to open source Rerun in the near future. If you're excited about being a part of that journey, sign up for our waitlist to get early access or a ping when it’s publicly available.