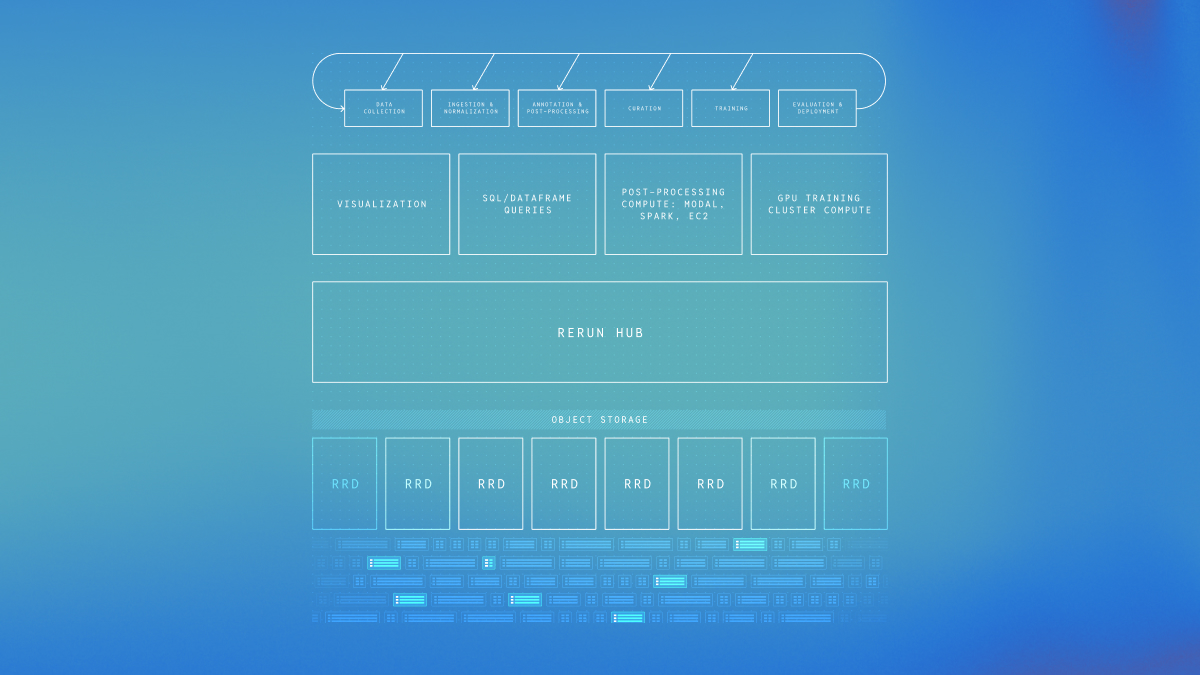
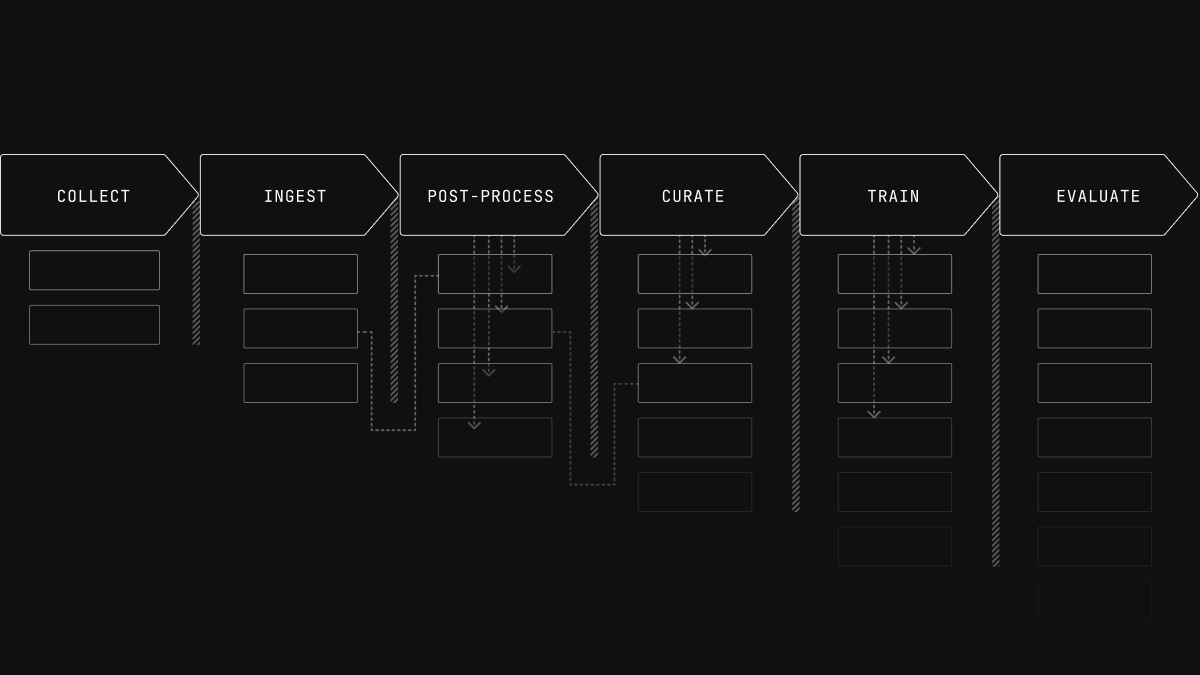
Dataframes from multimodal logs
Rerun is building the multimodal data stack for robotics and spatial intelligence. Up until now that has meant logging and visualization, but with the 0.19 release, we're expanding that in a big way.
Over the last year and a half, Rerun has been used by some of the best teams in the world that build intelligent products for the physical world. They have used Rerun to unify and simplify their visualization stacks to get a consistent view of their data; from notebook prototyping, monitoring a live robot, to debugging data pipelines for training.
Throughout that time we've been getting the same, very reasonable, question again and again: "how can I read back data from Rerun to use for analysis/training/random-use-case?". With Rerun 0.19 we can finally answer that question: by using the new dataframe query API from the SDK. To match, we've built a new dataframe view that lets you look at any data in Rerun as a table.
This new dataframe query API lets you load Rerun recordings and run queries against them that return Apache Arrow data. This makes it easy to pass results directly into your favorite dataframe tool like Pandas, Polars, or DuckDB. Another goal for this API is to enable you to easily create training datasets from your Rerun recordings, for example to use with 🤗 LeRobot.
That brings us to the next major feature in the 0.19 release, part 1 of native video support in Rerun. Modern imitation learning for robotics operate on sequences of images and storing those as videos has massive storage and performance benefits. This translates directly to iteration speed, which in turn means faster progress.
Part 1 of video means supporting video in mp4 files encoded with either AV1 (full support) or H.264 (only web viewer for now). Part 2 will be video streaming and bringing H.264 support to the native viewer as well. You can read about using the new AssetVideo archetype here, and more details on what's currently supported here.
SDK access to Rerun's query engine
At the heart of what makes Rerun fast, easy to use, and flexible is our time-aware Entity Component System data model and the query-engine that operates on it.
When you scroll the time-slider back and forth in the viewer, it's querying an in-memory database at 60fps for the latest versions of all components that are used for a visualization. In Rerun we call this a latest-at query, but in some systems something similar can also be called an AsOf Join.
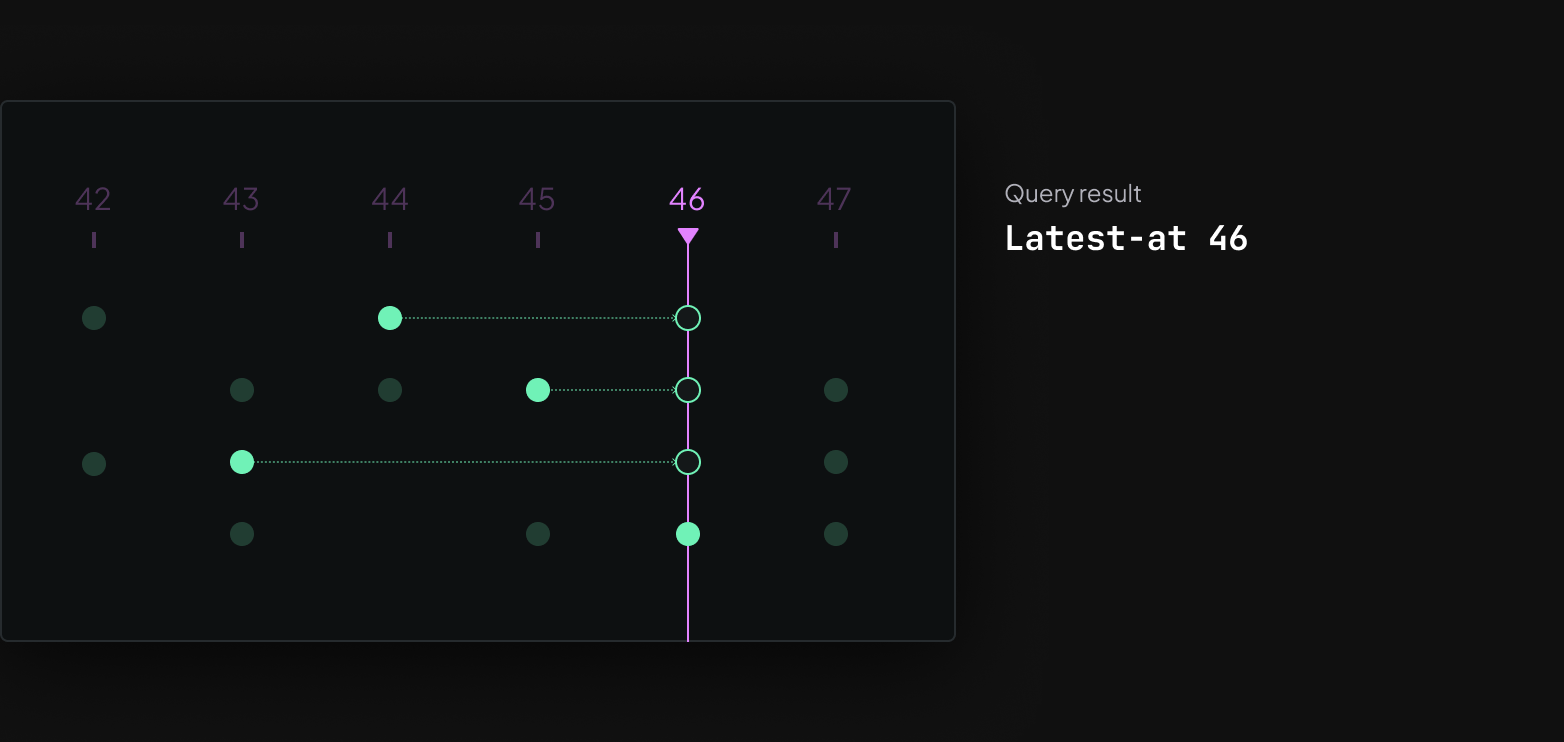
This is needed because data that's recorded from robotics-like systems are seldom aligned. For example, perception data like depth and color images tend to be generated at a much slower rate (15-60Hz) than motion IMU data (500-1000Hz). If you think of a recording as a table where each row is a timestamp, you tend to end up with very sparse tables.
Most systems for subsequent data analysis or training aren't built to handle these kinds of sparse tables, which means an important part of most data pipelines for robotics-like applications includes a time-alignment step. Time alignment can get pretty tricky which makes bugs common and code changes risky.
With the new dataframe query API, extracting a time aligned dataframe from a recording can be as simple as this:
import rerun as rr
import pyarrow.parquet as pq
recording = rr.dataframe.load_recording("/path/to/file.rrd")
batch_iterator = recording.view(index="frame_nr", # Use the frame_nr timeline as row-index
contents="/world/robot/**") # Include all data under /world/robot
.filter_is_not_null("/world/robot:Position3D") # Only rows containing this component
.fill_latest_at()
.select() # Select all columns
# Read into Pandas dataframe
df = batch_iterator.read_pandas()
...
# Or write to Parquet
with pq.ParquetWriter("train.parquet", batch_iterator.schema()) as writer:
for chunk in batch_iterator:
writer.write_batch(chunk)
Time-alignment can get a lot more complex that latest-at queries though, e.g. if you need to do motion interpolation, and we'll continue to expand these APIs to make that easier and easier to do with Rerun over time.
We're building robotics-style primitives into the database layer to simplify data pipelines
Our goal at Rerun is to make data pipelines much simpler to build and operate for teams working on spatial and embodied AI. We believe data should be visualizable and debuggable by default, wherever it is in the data pipeline. For that reason, data that uses the Rerun data model is directly visualizable in the Rerun Viewer. Using the Rerun SDK basically amounts to adding that semantic information to your data.
To make data pipelines easier to build, we think the database layer needs to actually understand robotics data. It's not enough to attach some semantics to specific robotics messages, all your data systems should maintain and use those semantics. As part of making that a reality we'll continue to push primitives for time-alignment, spatial transform resolution, label look-ups, and video-frame decoding into the database layer. The Rerun Viewer already does this and we'll expose more and more of these capabilities to the SDK over time.
This will all be part of Rerun's commercial offering, which is managed infrastructure to ingest, store, analyze, and stream data at scale with built-in visual debugging. It's currently in development with a few select design partners. Get in touch if you'd like to be one of them.
Try it out and let us know what you think
We're really looking forward to hear how the first pieces of both the dataframe query SDK and video support works for you. Start with the get data out of Rerun guide or the docs on AssetVideo and then join us on Github or Discord and let us know what you think and would hope to see in the future.